Lecture 12
pandas Basics - Reshaping DataFrames
February 24, 2025
Reshaping DataFrames
Reshaping DataFrames
Tidy DataFrames

- There are three interrelated rules that make a
DataFrametidy:- Each variable is a column; each column is a variable.
- Each observation is a row; each row is an observation.
- Each value is a cell; each cell is a single value.
Reshaping DataFrames
A
DataFramecan be given in a format unsuited for the analysis that we would like to perform on it.- A
DataFramemay have larger structural problems that extend beyond the data. - Perhaps the
DataFramestores its values in a format that makes it easy to extract a single row but difficult to aggregate the data.
- A
Reshaping a
DataFramemeans manipulating it into a different shape.In this section, we will discuss pandas techniques for molding a
DataFrameinto the shape we desire.
Long vs. Wide DataFrames
- The following
DataFramesmeasure temperatures in two cities over two days.
import pandas as pd
from google.colab import data_table
data_table.enable_dataframe_formatter()
df_wide = pd.DataFrame({
'Weekday': ['Tuesday', 'Wednesday'],
'Miami': [80, 83],
'Rochester': [57, 62],
'St. Louis': [71, 75]
})
df_long = pd.DataFrame({
'Weekday': ['Tuesday', 'Wednesday', 'Tuesday', 'Wednesday', 'Tuesday', 'Wednesday'],
'City': ['Miami', 'Miami', 'Rochester', 'Rochester', 'St. Louis', 'St. Louis'],
'Temperature': [80, 83, 57, 62, 71, 75]
})Long vs. Wide DataFrames
- A
DataFramecan store its values in wide or long format. - These names reflect the direction in which the data set expands as we add more values to it.
- A long
DataFrameincreases in height. - A wide
DataFrameincreases in width.
- A long
Long vs. Wide DataFrames
- The optimal storage format for a
DataFramedepends on the insight we are trying to glean from it.- We consider making
DataFrameslonger if one variable is spread across multiple columns. - We consider making
DataFrameswider if one observation is spread across multiple rows.
- We consider making
Reshaping DataFrames
melt() and pivot()
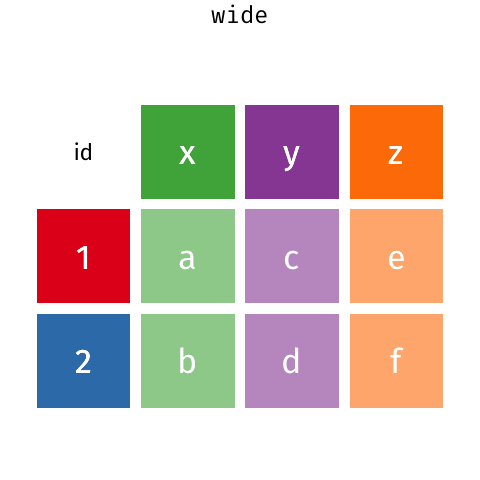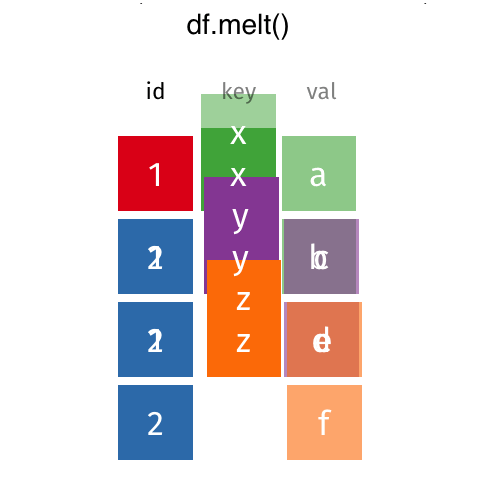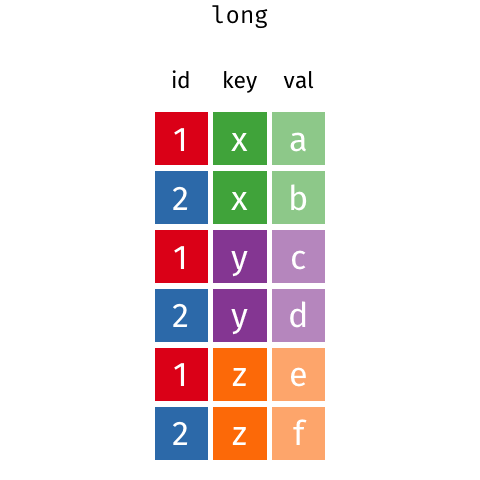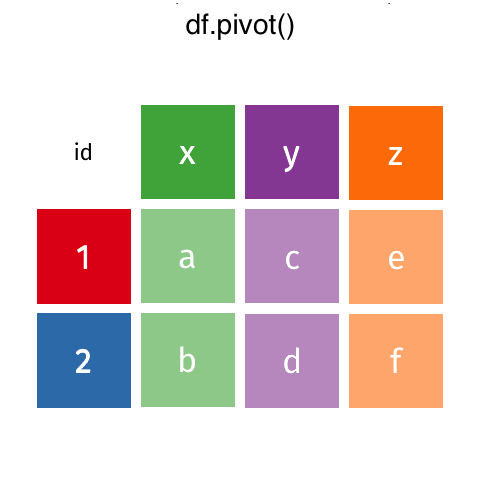
melt()makesDataFramelonger.pivot()makesDataFramewider.
Make DataFrame Longer with melt()
Make DataFrame Longer with melt()
melt()can take a few parameters:id_varsis a container (string,list,tuple, orarray) that represents the variables that will remain as is.id_varscan indicate which column should be the “identifier”.
Make DataFrame Longer with melt()
df_wide_to_long = (
df_wide
.melt(id_vars = "Weekday",
var_name = "City",
value_name = "Temperature")
)melt()can take a few parameters:var_nameis a string for the name of the variable whose values are taken from column names in a given wide-form DataFrame.value_nameis a string for the name of the variable whose values are taken from the values in a given wide-form DataFrame.
Make DataFrame Wider with pivot()
df_long_to_wide = (
df_long
.pivot(index = "Weekday",
columns = "City",
values = "Temperature"
)
.reset_index()
)- When using
pivot(), we need to specify a few parameters:indexthat takes the column to pivot on;columnsthat takes the column to be used to make the variable names of the widerDataFrame;valuesthat takes the column that provides the values of the variables in the widerDataFrame.
Reshaping DataFrames
- Let’s consider the following wide-form
DataFrame,df, containing information about the number of courses each student took from each department in each year.
dict_data = {"Name": ["Donna", "Donna", "Mike", "Mike"],
"Department": ["ECON", "DANL", "ECON", "DANL"],
"2018": [1, 2, 3, 1],
"2019": [2, 3, 4, 2],
"2020": [5, 1, 2, 2]}
df = pd.DataFrame(dict_data)
df_longer = df.melt(id_vars=["Name", "Department"],
var_name="Year",
value_name="Number of Courses")- The
pivot()method can also take alistof variable names for theindexparameter.
Reshaping DataFrames
- Let’s consider the following wide-form
DataFrame,df, containing information about the number of courses each student took from each department in each year.
dict_data = {"Name": ["Donna", "Donna", "Mike", "Mike"],
"Department": ["ECON", "DANL", "ECON", "DANL"],
"2022": [1, 2, 3, 1],
"2023": [2, 3, 4, 2],
"2024": [5, 1, 2, 2]}
df = pd.DataFrame(dict_data)
df_longer = df.melt(id_vars=["Name", "Department"],
var_name="Year",
value_name="Number of Courses")Q. How can we use the df_longer to create the wide-form DataFrame, df_wider, which is equivalent to the df?
Reshaping DataFrames
Let’s do Part 1 of Classwork 7!