Lecture 13
Data Preparation and Management
Byeong-Hak Choe
SUNY Geneseo
September 27, 2024
Technologies Used to Manage and Process Big Data
Hadoop
Introduction to Hadoop
- Definition
- An open-source software framework for storing and processing large data sets.
- Components
- Hadoop Distributed File System (HDFS): Distributed data storage.
- MapReduce: Data processing model.
Hadoop
Introduction to Hadoop
- Purpose
- Enables distributed processing of large data sets across clusters of computers.
Hadoop
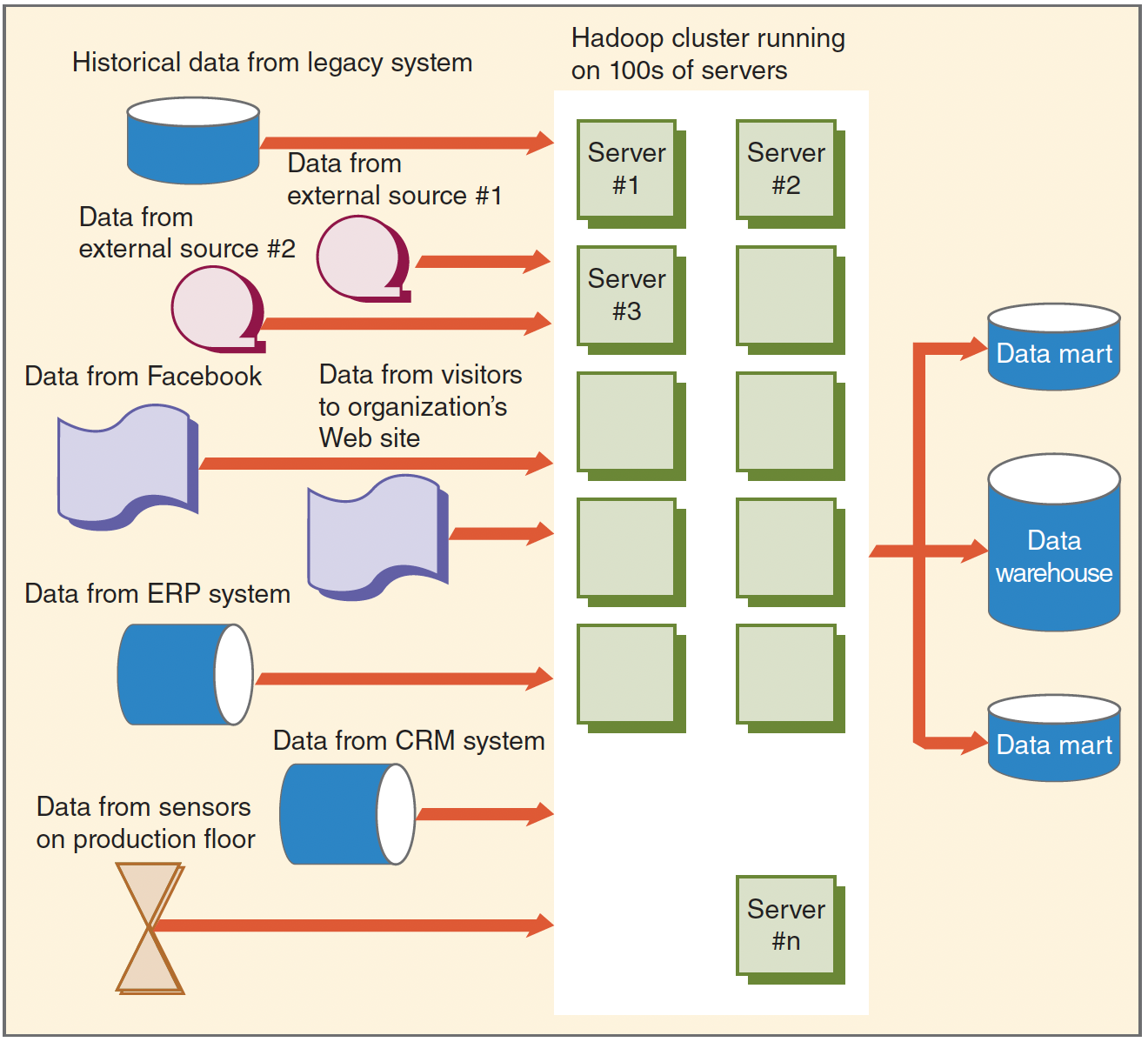
Hadoop Architecture - HDFS
- HDFS
- Divides data into blocks and distributes them across different servers for processing.
- Provides a highly redundant computing environment
- Allows the application to keep running even if individual servers fail.
Hadoop
Hadoop Architecture - MapReduce
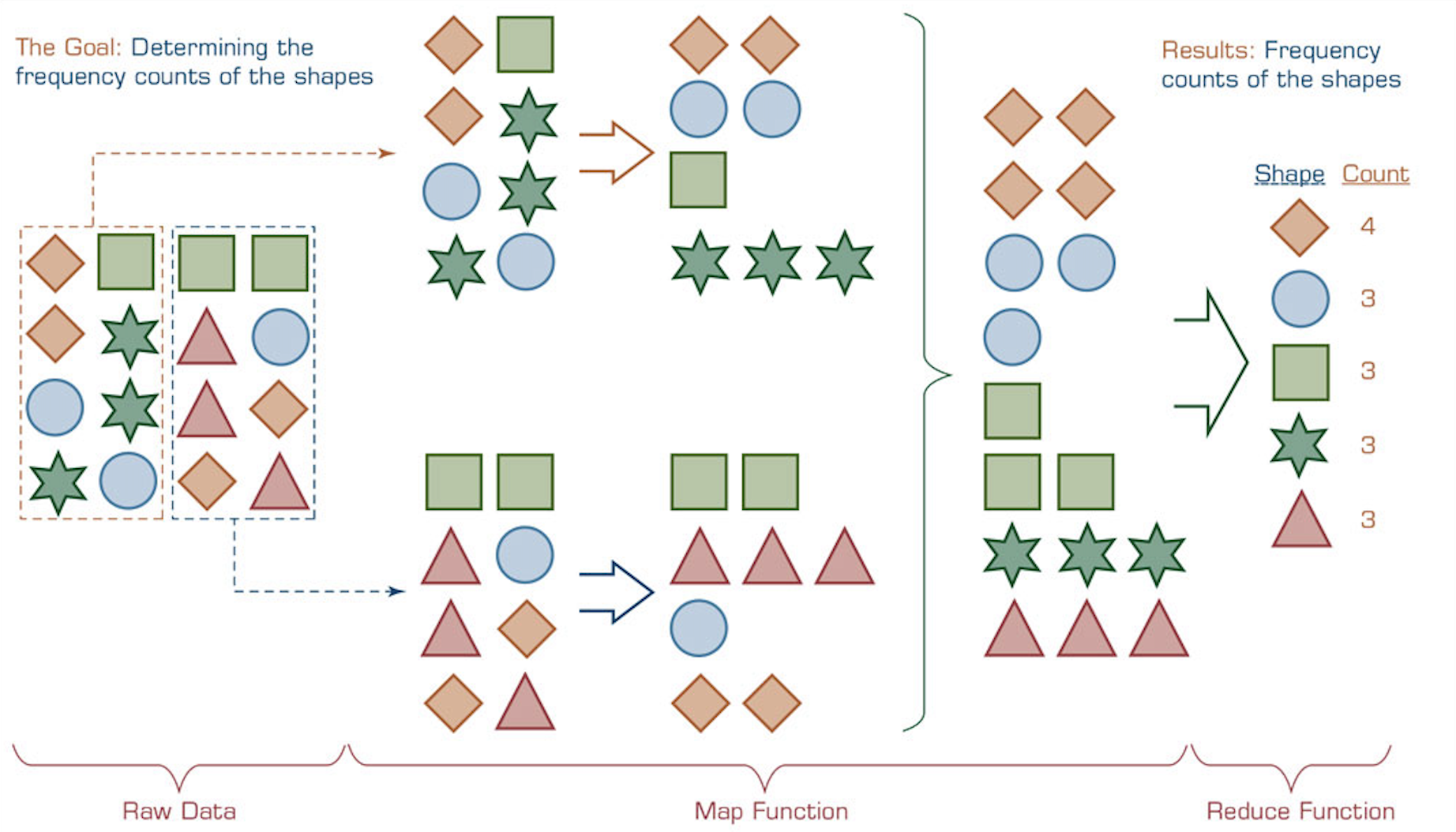
- MapReduce
- Map Phase: Filters and sorts data.
- e.g., Sorting customer orders based on their product IDs, with each group corresponding to a specific product ID.
- Reduce Phase: Summarizes and aggregates results.
- e.g., Counting the number of orders within each group, thereby determining the frequency of each product ID.
Hadoop
Hadoop Architecture - MapReduce
Hadoop
How Hadoop Works
- Data Distribution
- Large data sets are split into smaller blocks.
- Data Storage
- Blocks are stored across multiple servers in the cluster.
- Processing with MapReduce
- Map Tasks: Executed on servers where data resides, minimizing data movement.
- Reduce Tasks: Combine results from map tasks to produce final output.
- Fault Tolerance
- Data replication ensures processing continues even if servers fail.
Hadoop
Extending Hadoop for Real-Time Processing
- Limitation of Hadoop
- Hadoop is originally designed for batch processing.
- Batch Processing: Data or tasks are collected over a period of time and then processed all at once, typically at scheduled times or during periods of low activity.
- Results come after the entire dataset is analyzed.
- Real-Time Processing Limitation:
- Hadoop cannot natively process real-time streaming data (e.g., stock prices flowing into stock exchanges, live sensor data)
- Extending Hadoop’s Capabilities
- Both Apache Storm and Apache Spark can run on top of Hadoop clusters, utilizing HDFS for storage.
Hadoop
Apache Storm and Apache Spark
Apache Storm
- Functionality:
- Processes real-time data streams.
- Handles unbounded streams of data reliably and efficiently.
- Use Cases:
- Real-time analytics
- Online machine learning
- Continuous computation
- Real-time data integration
Apache Spark
- Functionality:
- Provides in-memory computations for increased speed.
- Supports both batch and streaming data processing through Spark Streaming.
- Use Cases:
- Interactive queries for quick, on-the-fly data analysis
- Machine learning
Apache Storm and Apache Spark
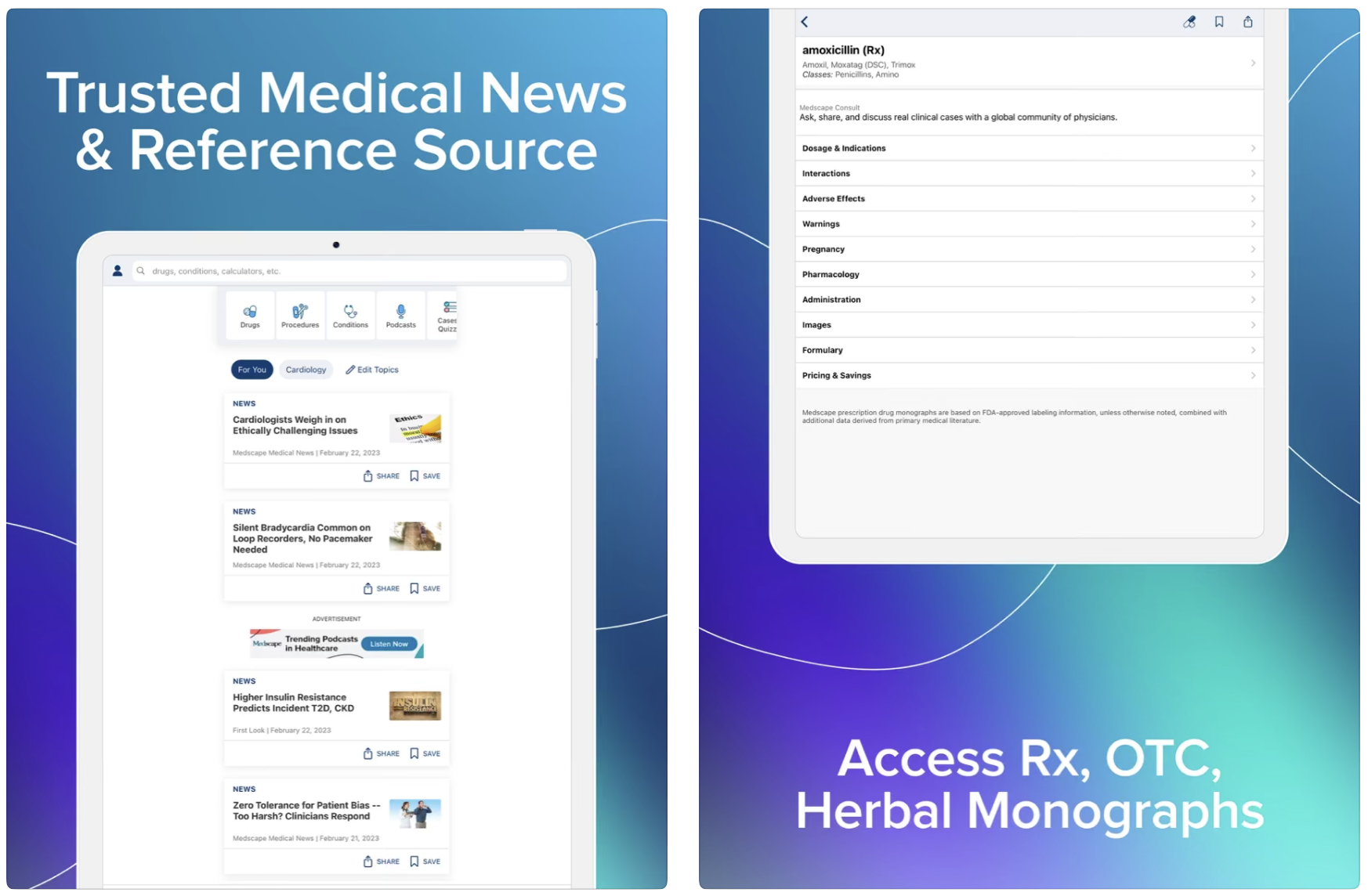
Medscape: Real-Time Medical News for Healthcare Professionals
- A medical news app for smartphones and tablets designed to keep healthcare professionals informed.
- Provides up-to-date medical news and expert perspectives.
- Real-Time Updates:
- Uses Apache Storm to process about 500 million tweets per day.
- Automatic Twitter feed integration helps users track important medical trends shared by physicians and medical commentators.