Lecture 12
Data Preparation and Management
September 25, 2024
Data Warehouses, Data Marts, and Data Lakes
Data Warehouses
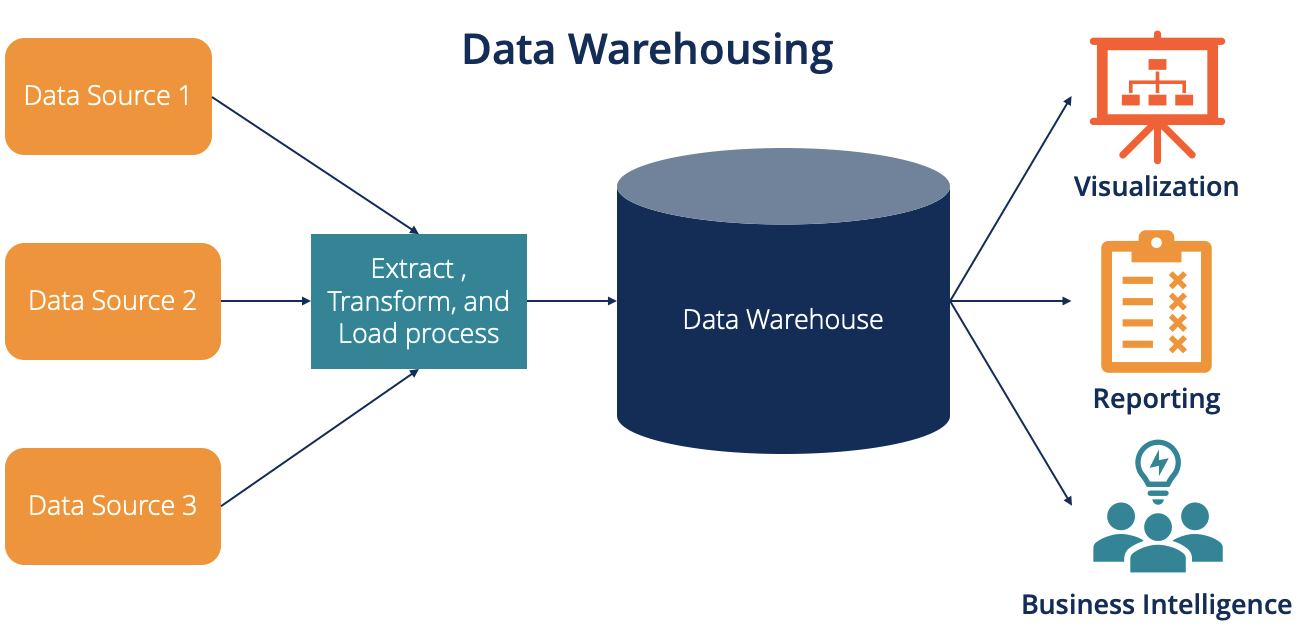
- Definition
- A large database that holds business information from many sources across the enterprise.
- Purpose
- Supports decision-making processes by providing a comprehensive view of the organization’s data.
Data Warehouses, Data Marts, and Data Lakes
Examples of Data Warehouse Usage

- Walmart
- Early adopter; used data warehouse to gain a competitive advantage in supply chain management.
- Held transaction data from over 11,000 stores and 25,000 suppliers.
- First commercial data warehouse to reach 1 terabyte in 1992.
- Collects data over 2.5 petabytes per hour in 2024.
Data Warehouses, Data Marts, and Data Lakes
Examples of Data Warehouse Usage
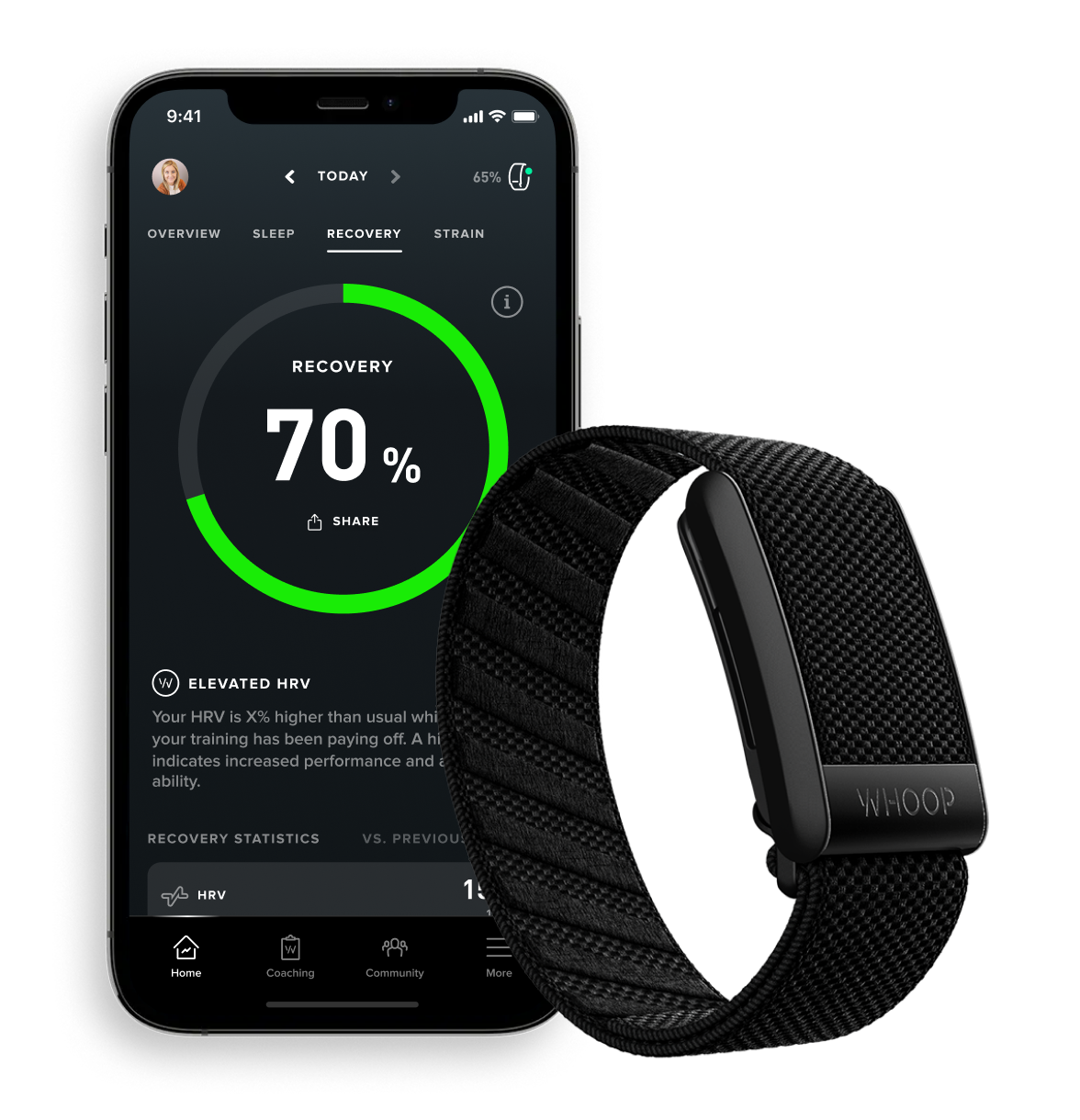
- WHOOP Wearable Device
- Collects massive biometric data from athletes.
- Data warehouse stores sensor data collected 100 times per second.
- Provides insights on strain, recovery, and sleep to optimize performance.
Data Warehouses, Data Marts, and Data Lakes
Examples of Data Warehouse Usage

- American Airlines
- Flight attendants access customer data to enhance in-flight service.
- Ability to resolve issues by offering free miles or travel vouchers based on customer history.
Data Lakes
Case Study: Bechtel Corporation

- About Bechtel
- Global engineering, construction, and project management company.
- Implementation
- Built a 5-petabyte data lake consolidating years of project data.
Relational Databases
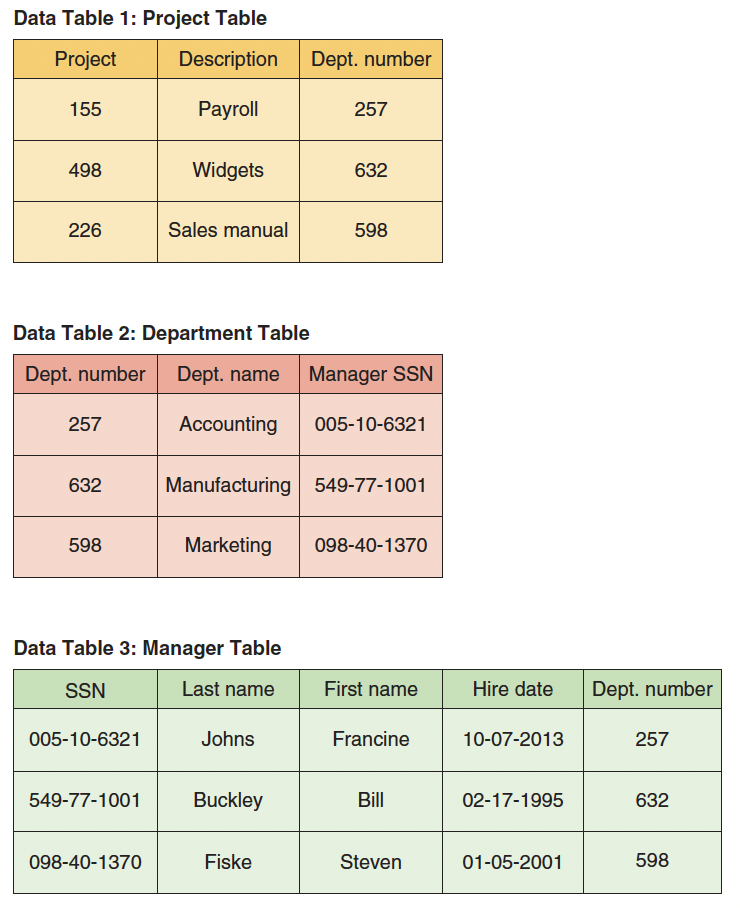
- The relational database model is a simple but highly useful way to organize data into collections of two-dimensional tables called relations.