Lecture 7
Big Data and the Modern Data Infrastructure
October 15, 2025
Structured Data vs. Unstructured Data
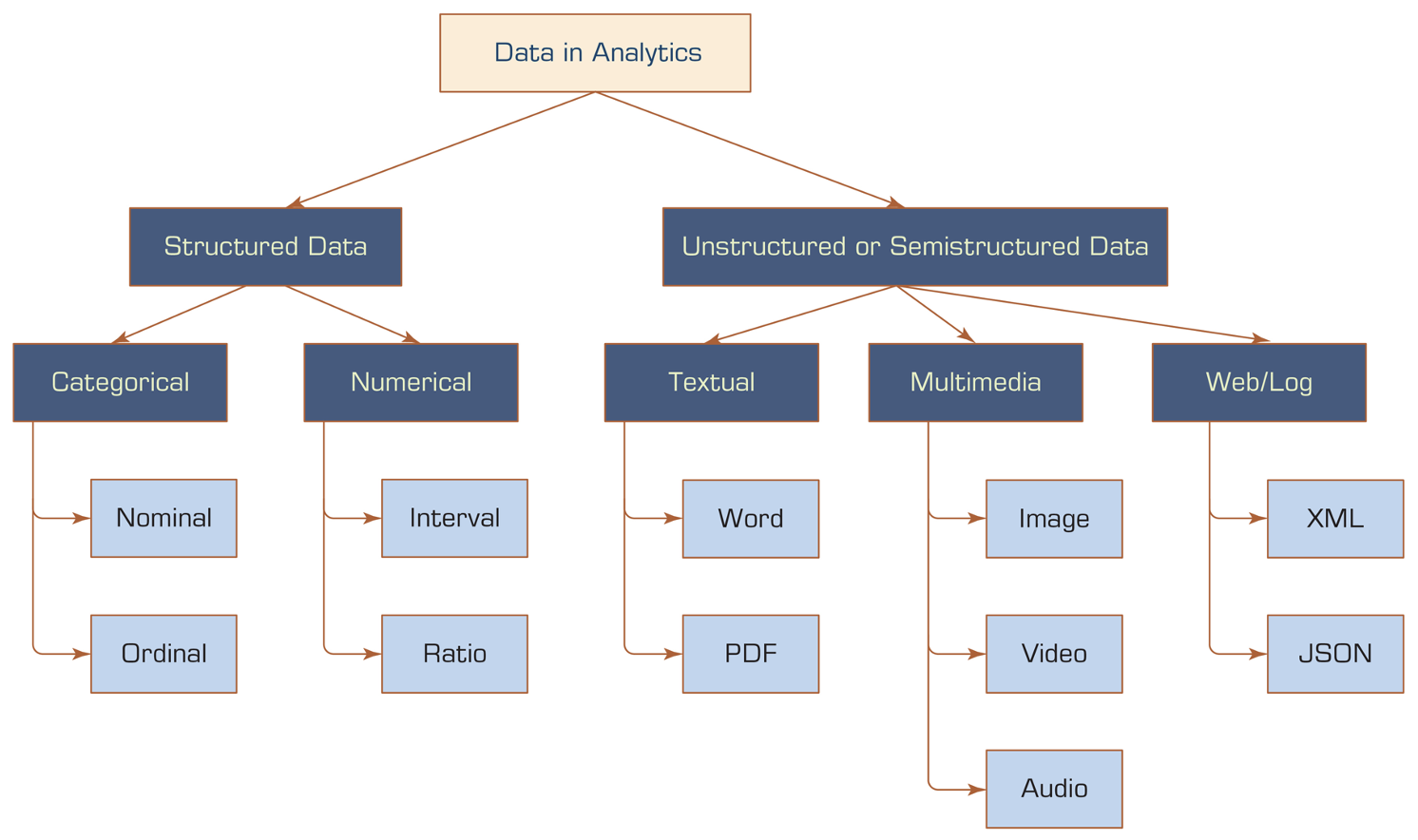
- Data comes in various formats.
- Structured data: Has a predefined format, fits into traditional databases.
- Unstructured data: Not organized in a predefined manner, comes from sources like documents, social media, emails, photos, videos, etc.
Relational Databases
- When multiple tables are linked by keys, this structure is called a relational database
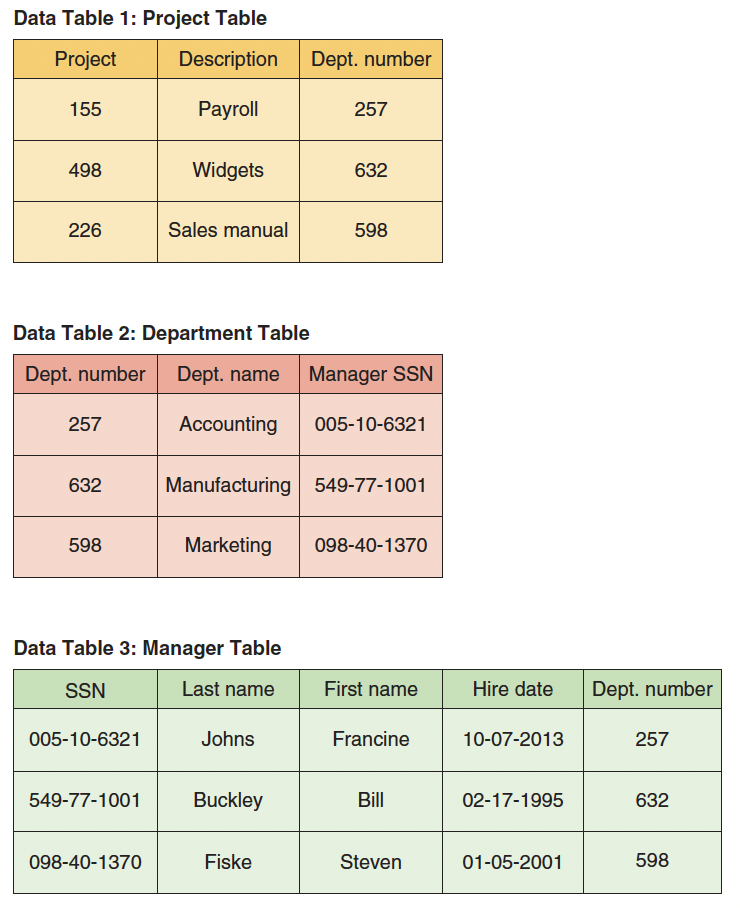
tab_project <-
read_csv("https://bcdanl.github.io/data/rdb-project_table.csv")
tab_department <-
read_csv("https://bcdanl.github.io/data/rdb-department_table.csv")
tab_manager <-
read_csv("https://bcdanl.github.io/data/rdb-manager_table.csv")- A relational database organizes data into multiple related tables, called relations.
- Each table stores data about one type of entity (e.g., projects, departments, managers).
Relational Tables and Keys
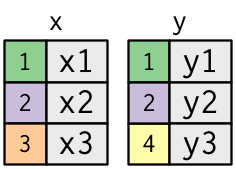
- The colored column represents the “key” variable (
key). - The grey column represents the “value” variable (
val_x,val_y).
Joining Tables with left_join()
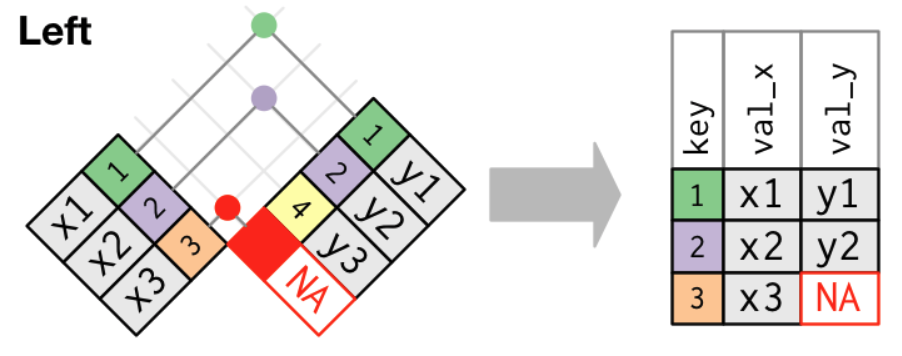
- A left join keeps all rows from
xand adds matching information fromy. - Among the different join types,
left_join()is the most commonly used join.- It does not lose information from your main data.frame (
x) and simply attaches extra information (y) when it exists.
- It does not lose information from your main data.frame (
- Try it out → Classwork 9: ETL Process in R.
1️⃣ Volume
| Unit | Symbol | Value |
|---|---|---|
| Kilobyte | kB | 10³ |
| Megabyte | MB | 10⁶ |
| Gigabyte | GB | 10⁹ |
| Terabyte | TB | 10¹² |
| Petabyte | PB | 10¹⁵ |
| Exabyte | EB | 10¹⁸ |
| Zettabyte | ZB | 10²¹ |
| Yottabyte | YB | 10²⁴ |
| Brontobyte* | BB | 10²⁷ |
| Gegobyte* | GeB | 10³⁰ |
*Less commonly used or proposed extensions.
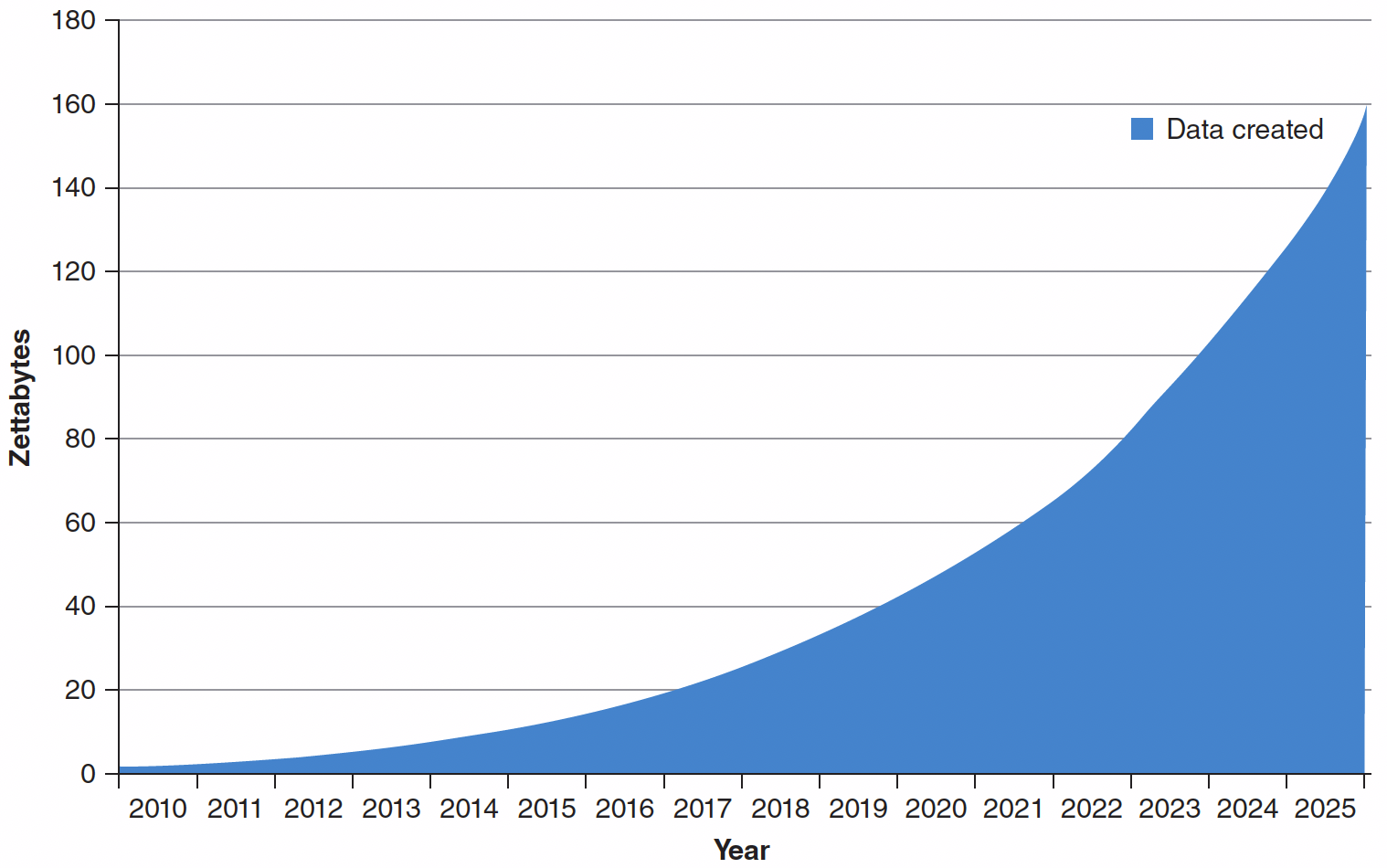
Growth of the Global Datasphere
- In 2017, the digital universe contained 16.1 zettabytes of data.
- Expected to grow to 163 zettabytes by 2025.
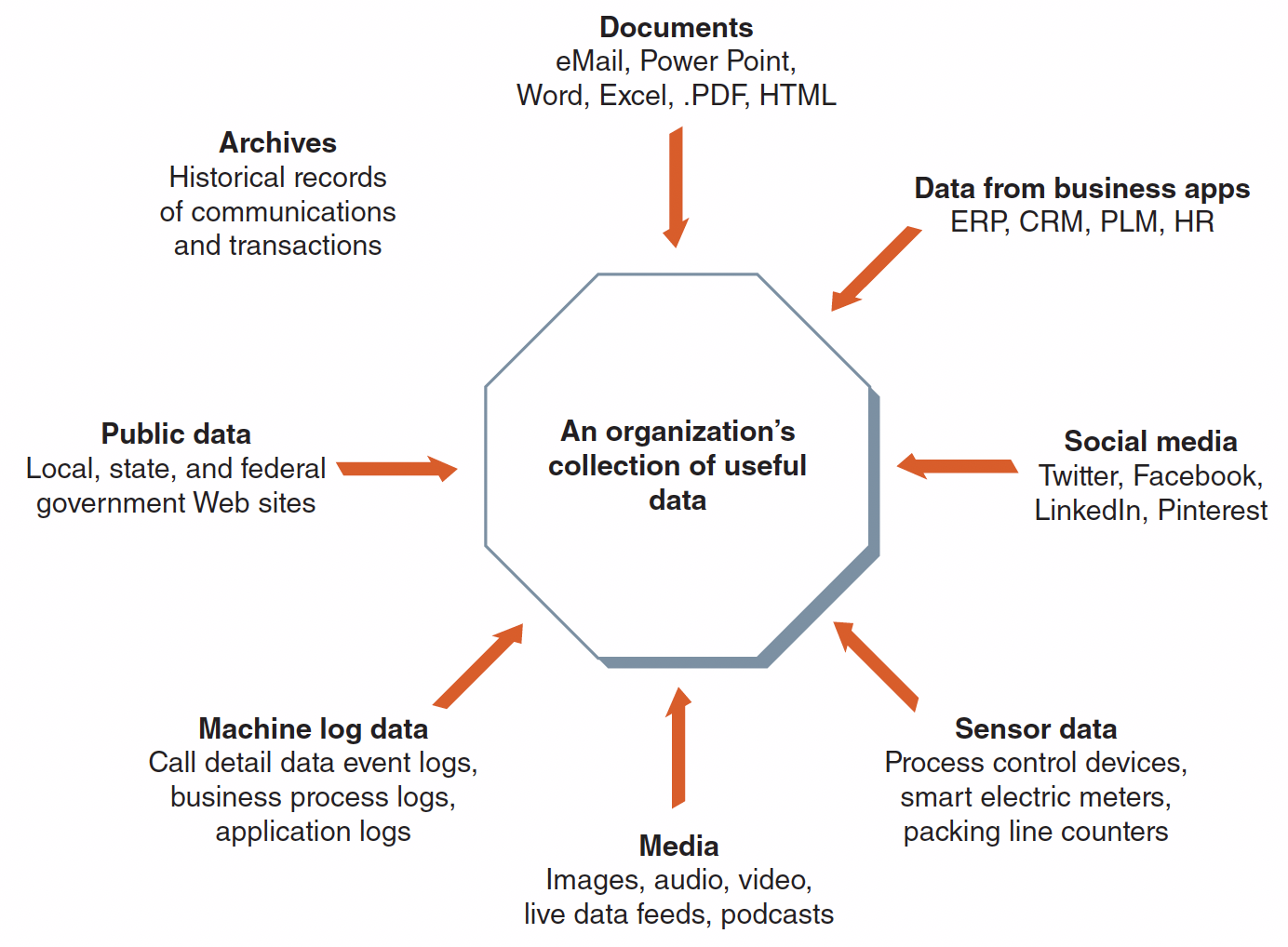
5️⃣ Variety
Data Warehouses
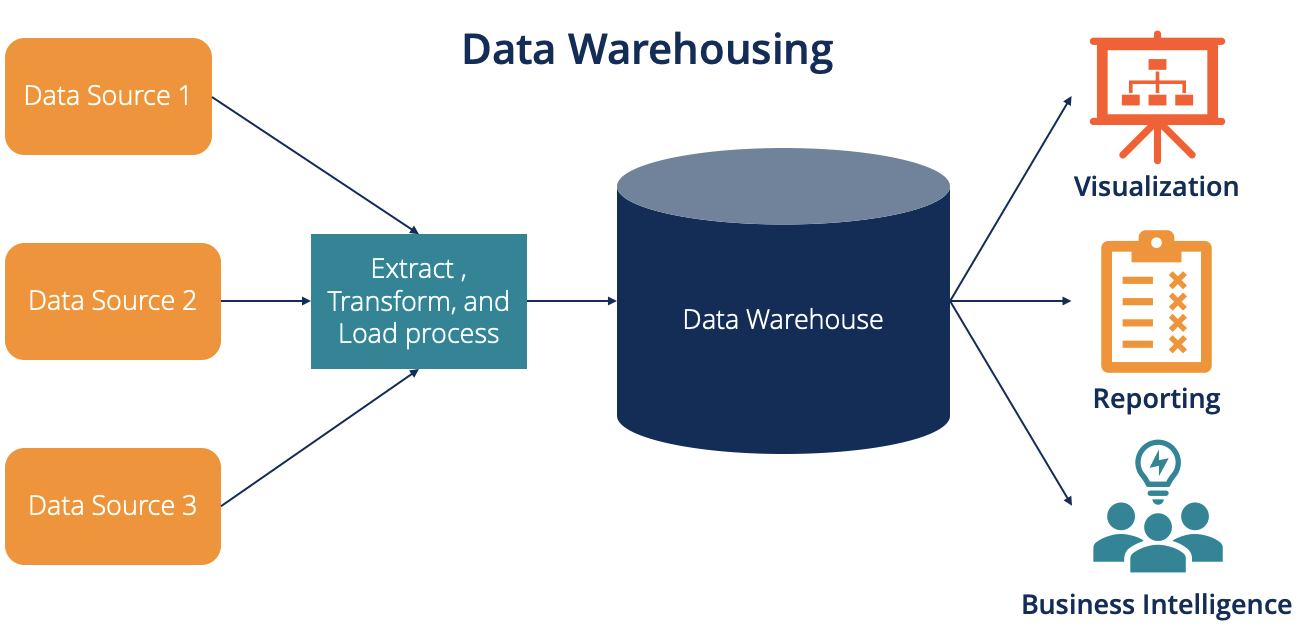
- Definition: Central repository integrating data from multiple sources.
- Purpose: Enables comprehensive analysis and decision-making.
Walmart: A Pioneer in Data Warehousing

Early adopter of data-driven supply chain optimization
Collects transaction data from 11,000+ stores and 25,000 suppliers
Uses real-time analytics to optimize pricing, inventory, and customer experience
In 1992, launched the first commercial data warehouse to exceed 1 TB
In 2025, processes data at a rate of 2.5 petabytes per hour