Lecture 5
R Basics and Descriptive Statistics
September 17, 2025
Posit Cloud Environment
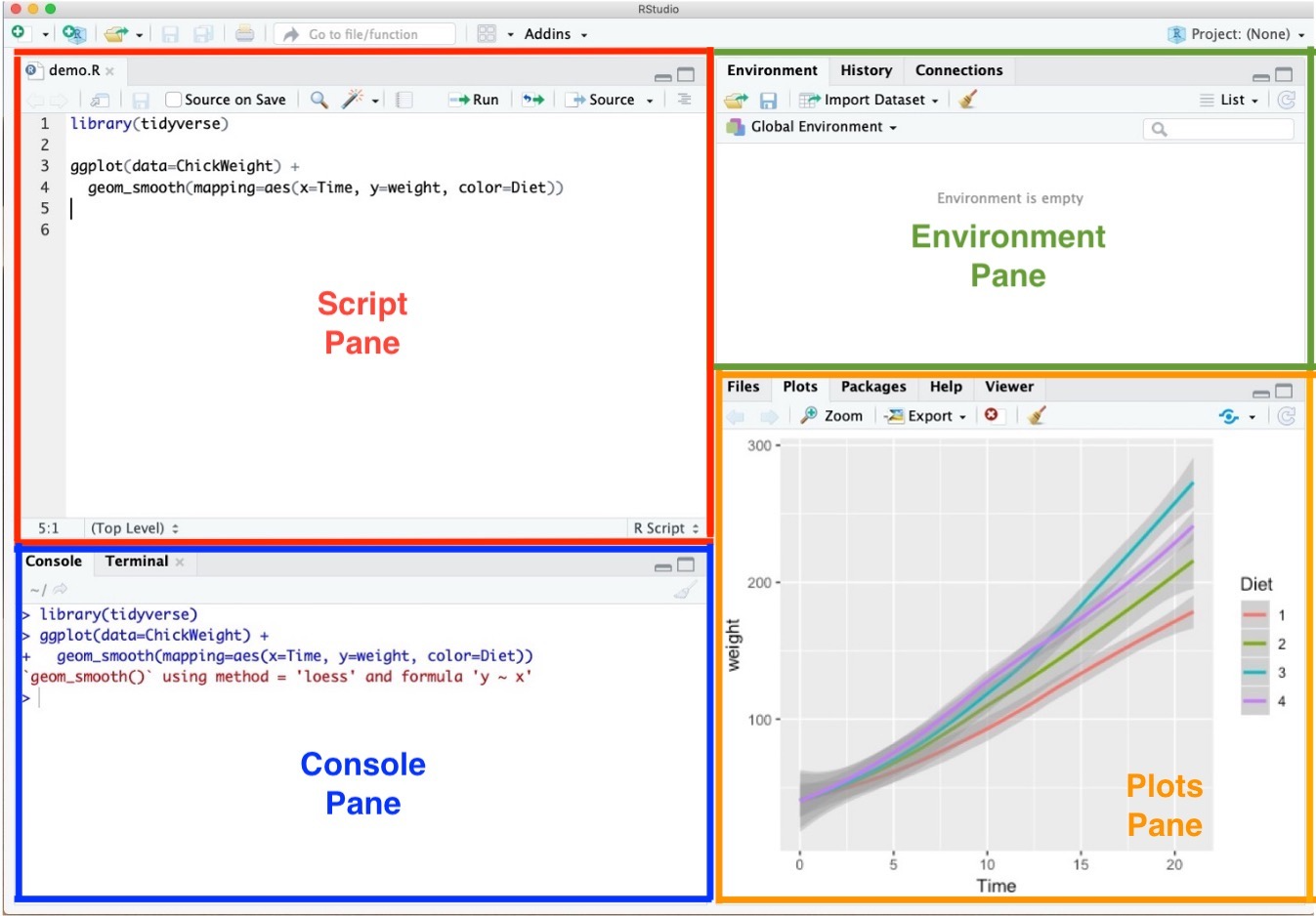
- Script Pane is where you write and save R commands in a script file.
- An R script is simply a plain text file containing R code.
- Posit Cloud (RStudio Cloud) automatically color-codes your code to make it easier to read.
- An R script is simply a plain text file containing R code.
- Try typing
a <- 1in the Script Pane.- With the cursor ( ┃ ) on the same line, run the code using:
- Ctrl + Enter (Windows)
- Command + Enter (Mac)
- Ctrl + Enter (Windows)
- With the cursor ( ┃ ) on the same line, run the code using:
Posit Cloud Environment
- Console Pane allows you to interact directly with the R interpreter and type commands where R will immediately execute them.
Posit Cloud Environment
- Environment Pane shows everything you have created in R so far.
- For example, if you make a variable or a data frame, it will appear here.
- Think of it like a workspace where R keeps track of all the things you’re working on.
- For example, if you make a variable or a data frame, it will appear here.
Posit Cloud Environment
- Plots Pane contains any graphics that you generate from your R code.
🌐 tidyverse
- The
tidyverseis a collection of R packages built for data analytics.- They share a common design philosophy, grammar, and data structures.
- Popular packages in the
tidyverseinclude:- readr → data reading
- dplyr → data transformation
- ggplot2 → data visualization

Workflow: Auto-completion
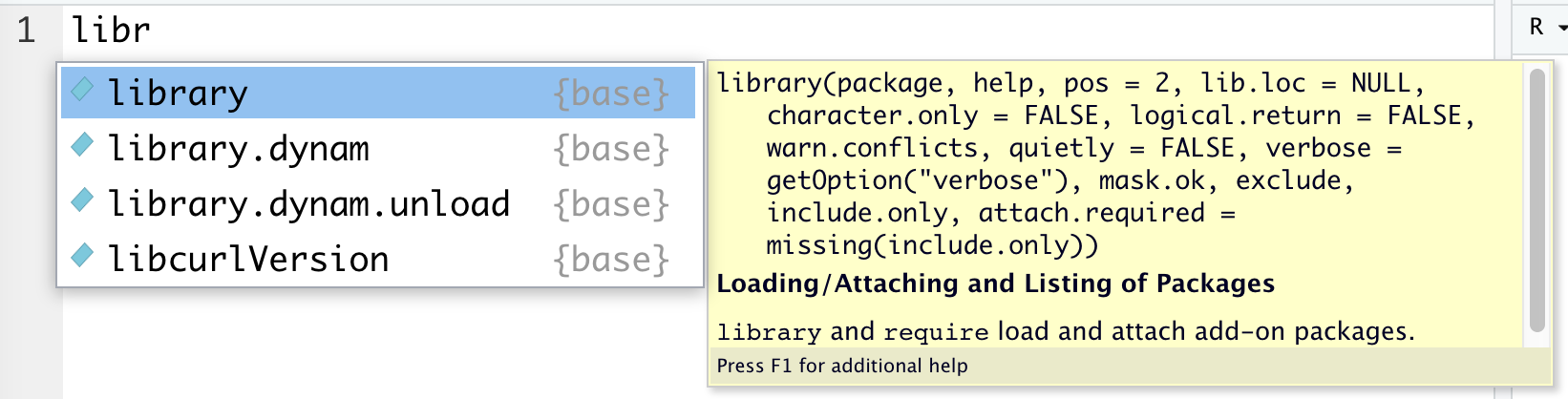
- Auto-completion of command is useful.
- Type
librin the RScript in RStudio and wait for a second.
- Type
Workflow: STOP icon
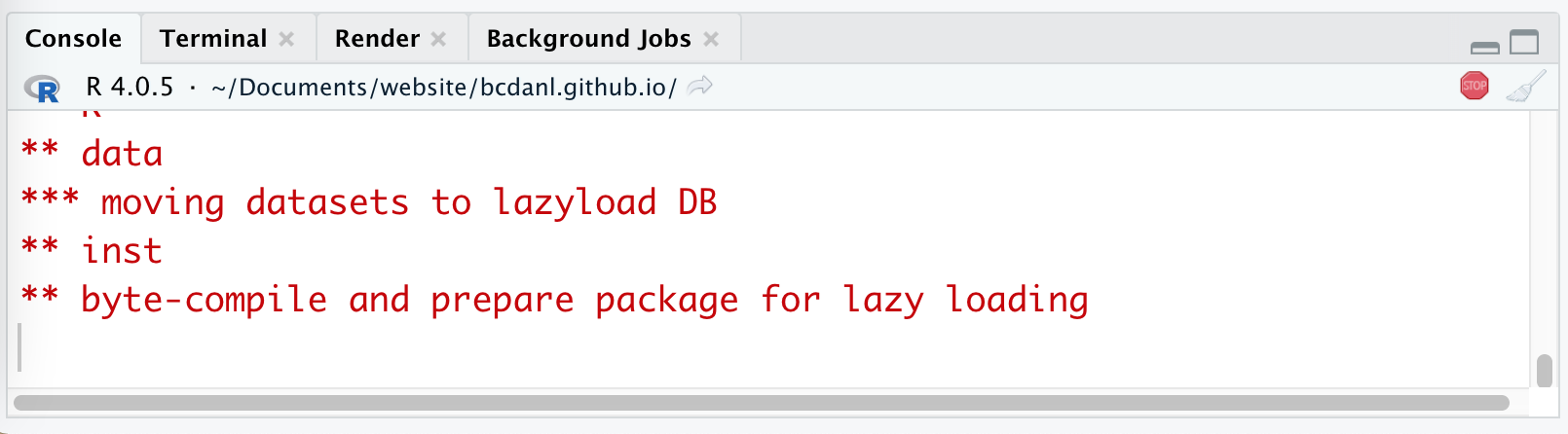
- When the code is running, RStudio shows the STOP icon ( 🛑 ) at the top right corner in the Console Pane.
- Do not click it unless if you want to stop running the code.
Posit Cloud Options Setting
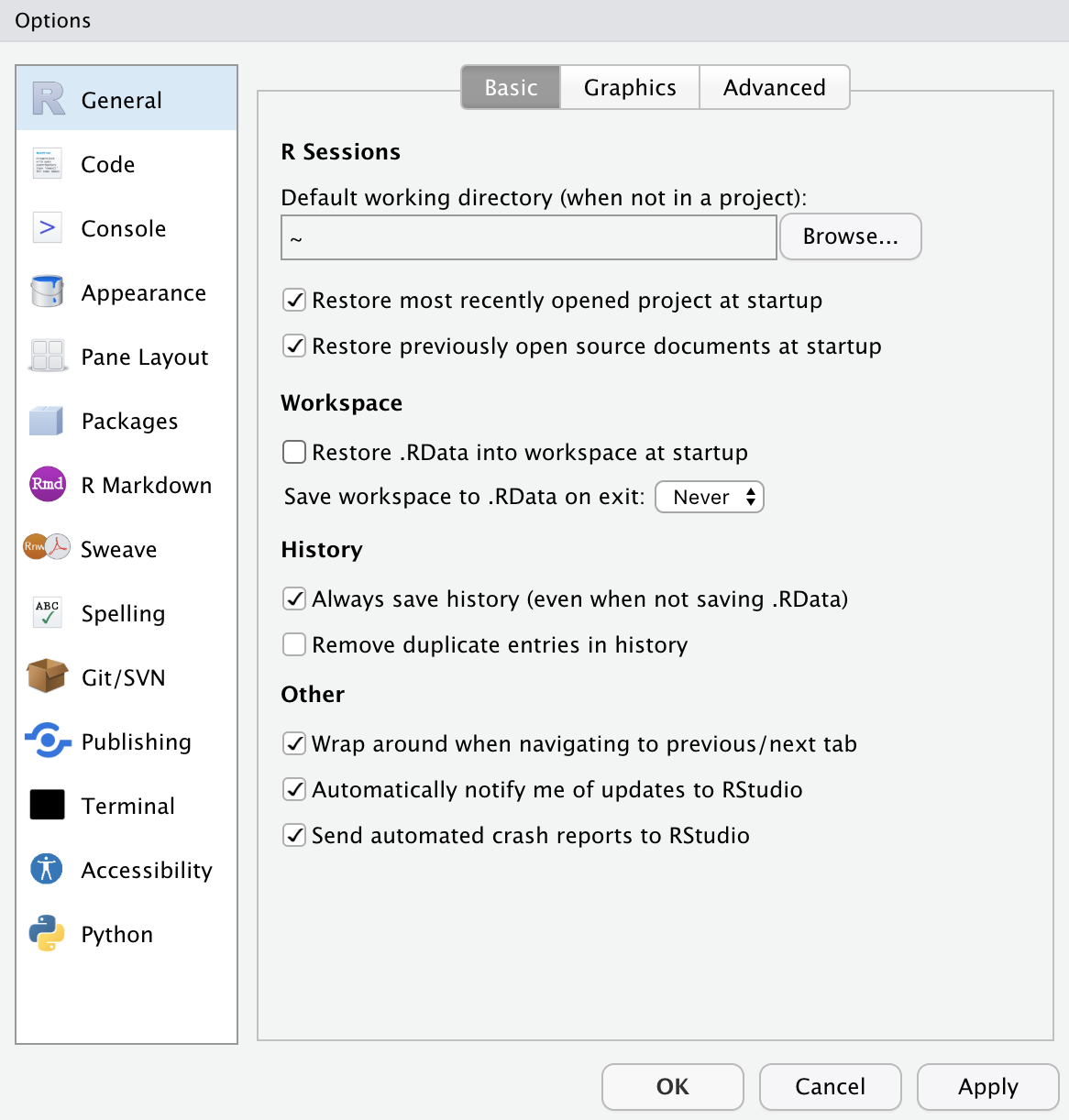
- This option menu is found by menus as follows:
- Tools \(>\) Global Options
- Check the boxes as in the left.
- Choose the option Never for Save workspace to .RData on exit:
Values, Variables, and Data Types

A value is datum (literal) such as a number or text.
There are different types of values:
- 352.3 is known as a float or double;
- 22 is an integer;
- “Hello World!” is a string.
Values, Variables, and Data Types
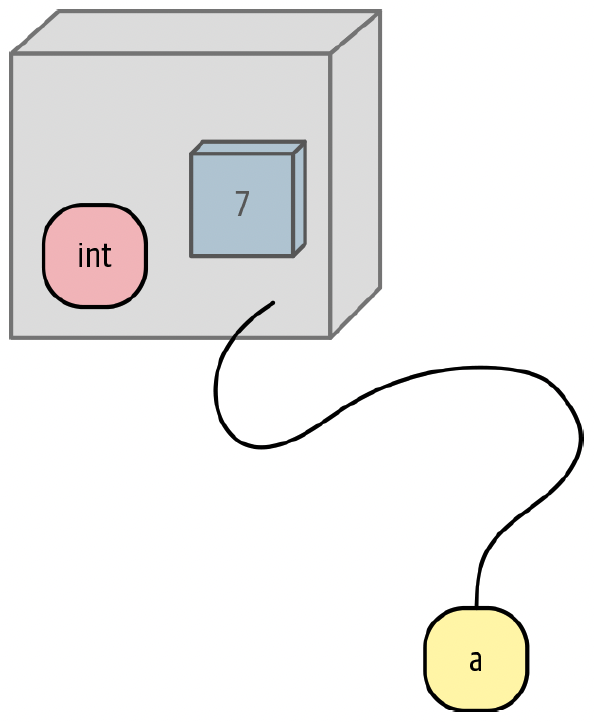
A variable is a name that refers to a value.
- We can think of a variable as a box that has a value, or multiple values, packed inside it.
A variable is just a name!
Sometimes you will hear variables referred to as objects. m
Everything that is not a literal value, such as
10, is an object.
Data Types

- Logical:
TRUEorFALSE. - Numeric: Numbers with decimals
- Integer: Integers
- Character: Text strings
- Factor: Categorical values.
- Each possible value of a factor is known as a level.
Data Containers
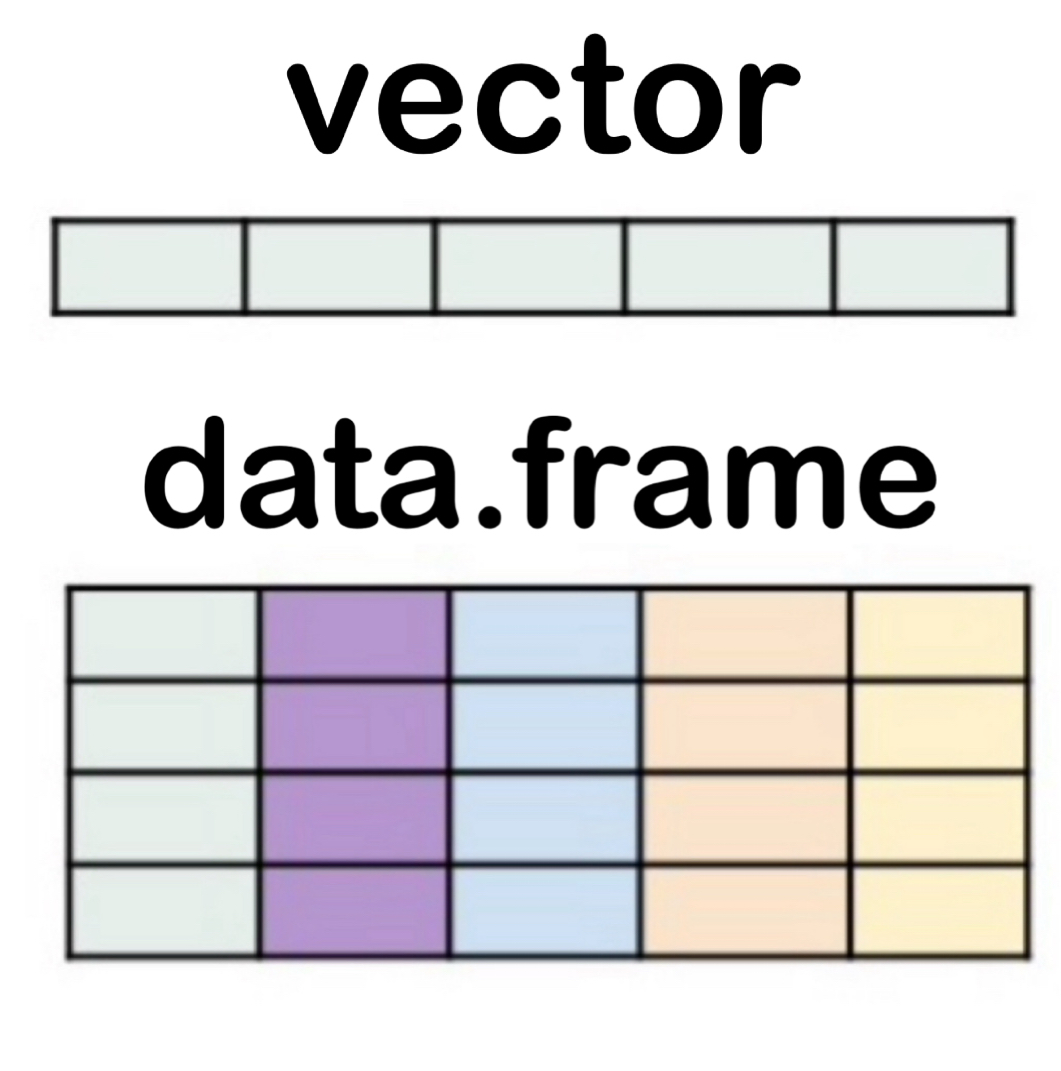
- vector → a single column of values, all of the same type
- Example:
c(1, 2, 3)c("red", "blue", "green")
- Example:
- data.frame → a table with rows and columns, where each column can be a different type
- Example: one column with
names, another withages
- A data.frame is basically several vectors put together side by side.
- Example: one column with
Descriptive Statistics
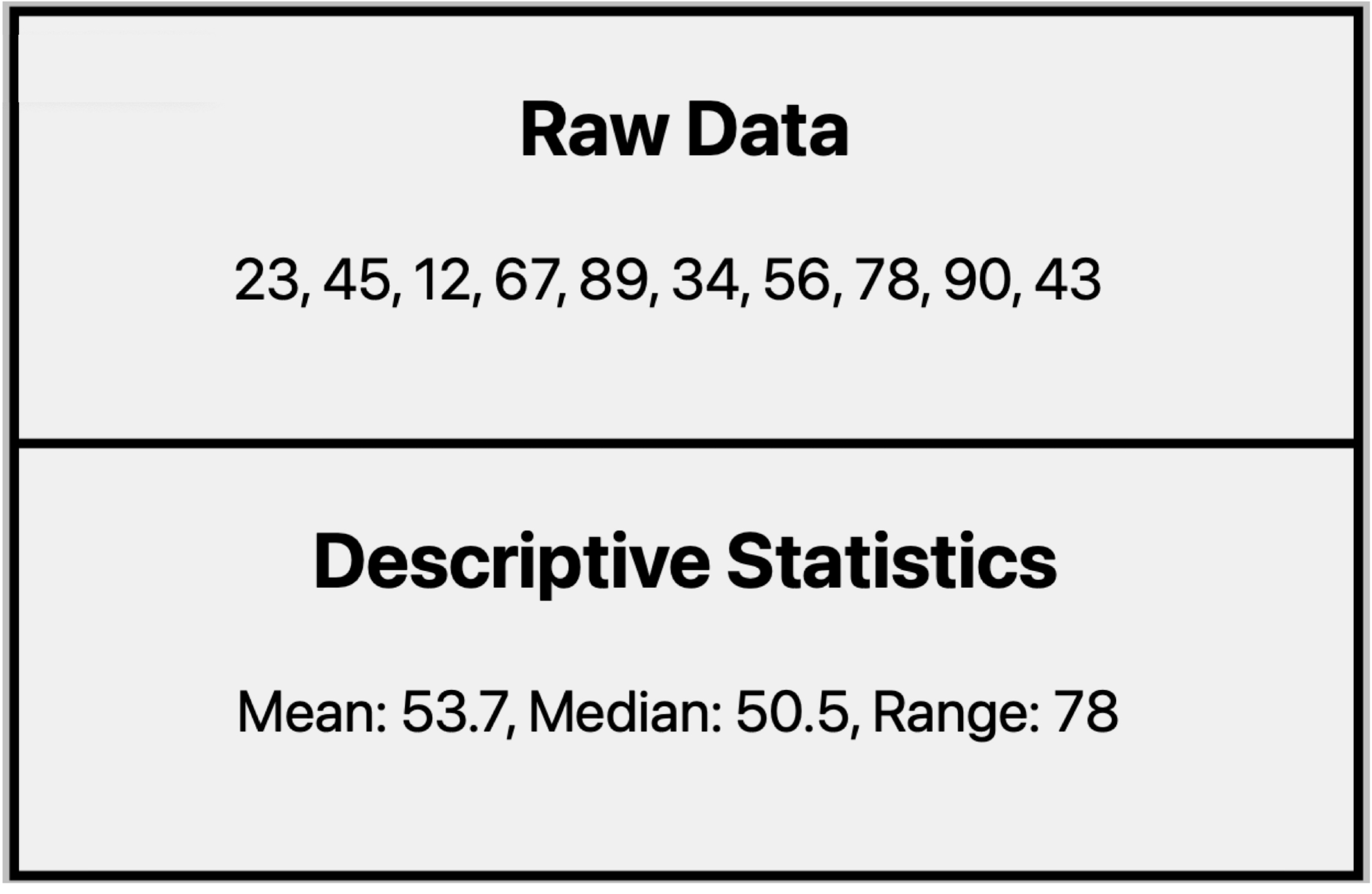
What can descriptive statistics tell us about this dataset?
- They condense data into clear, manageable summaries, making it easier to understand the key characteristics of a dataset.
- They reveal important patterns, trends, and relationships that may not be immediately obvious from raw numbers.
Measures of Central Tendency - Median


- The median is the middle value in a vector—half the numbers are smaller and half are larger.
median()calculates the median of the values in a vector.
- The median is less sensitive to extreme values than the mean.
Measures of Dispersion – Interquartile Range
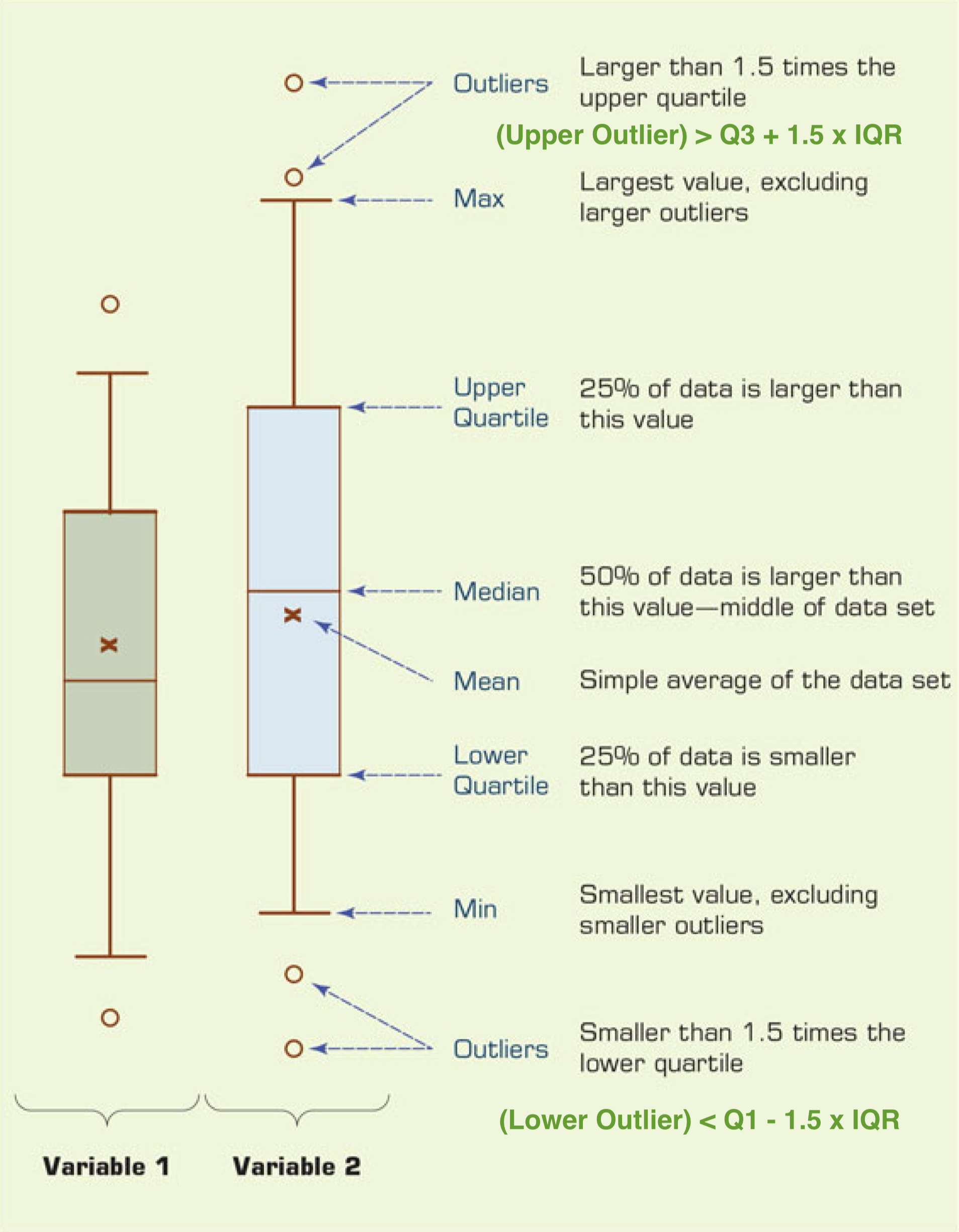
Boxplot
- The interquartile range (IQR) is \(IQR = Q3 - Q1\).
- It measures the spread of the middle 50% of the data.
- A popular way to visualize quartiles and the IQR is a boxplot.
- It measures the spread of the middle 50% of the data.
- Why quartiles are useful
- Quartiles show whether the data are more spread out in the lower half or the upper half of the dataset.
- Quartiles are less sensitive to extreme values (outliers) than the mean.
- Quartiles show whether the data are more spread out in the lower half or the upper half of the dataset.