import pandas as pd
import numpy as np
from tabulate import tabulate # for table summary
import scipy.stats as stats
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm # for lowess smoothing
from pyspark.sql import SparkSession
from pyspark.sql.functions import rand, col, pow, mean, avg, when, log, sqrt, exp
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import LinearRegression
spark = SparkSession.builder.master("local[*]").getOrCreate()Linear Regression
Bikeshare in DC
Settings
Required Libraries and Spark Session
UDFs
regression_table
Code
def regression_table(model, assembler):
"""
Creates a formatted regression table from a fitted LinearRegression model and its VectorAssembler.
If the model’s labelCol (retrieved using getLabelCol()) starts with "log", an extra column showing np.exp(coeff)
is added immediately after the beta estimate column for predictor rows. Additionally, np.exp() of the 95% CI
Lower and Upper bounds is also added unless the predictor's name includes "log_". The Intercept row does not
include exponentiated values.
When labelCol starts with "log", the columns are ordered as:
y: [label] | Beta | Exp(Beta) | Sig. | Std. Error | p-value | 95% CI Lower | Exp(95% CI Lower) | 95% CI Upper | Exp(95% CI Upper)
Otherwise, the columns are:
y: [label] | Beta | Sig. | Std. Error | p-value | 95% CI Lower | 95% CI Upper
Parameters:
model: A fitted LinearRegression model (with a .summary attribute and a labelCol).
assembler: The VectorAssembler used to assemble the features for the model.
Returns:
A formatted string containing the regression table.
"""
# Determine if we should display exponential values for coefficients.
is_log = model.getLabelCol().lower().startswith("log")
# Extract coefficients and standard errors as NumPy arrays.
coeffs = model.coefficients.toArray()
std_errors_all = np.array(model.summary.coefficientStandardErrors)
# Check if the intercept's standard error is included (one extra element).
if len(std_errors_all) == len(coeffs) + 1:
intercept_se = std_errors_all[0]
std_errors = std_errors_all[1:]
else:
intercept_se = None
std_errors = std_errors_all
# Use provided tValues and pValues.
df = model.summary.numInstances - len(coeffs) - 1
t_critical = stats.t.ppf(0.975, df)
p_values = model.summary.pValues
# Helper: significance stars.
def significance_stars(p):
if p < 0.01:
return "***"
elif p < 0.05:
return "**"
elif p < 0.1:
return "*"
else:
return ""
# Build table rows for each feature.
table = []
for feature, beta, se, p in zip(assembler.getInputCols(), coeffs, std_errors, p_values):
ci_lower = beta - t_critical * se
ci_upper = beta + t_critical * se
# Check if predictor contains "log_" to determine if exponentiation should be applied
apply_exp = is_log and "log_" not in feature.lower()
exp_beta = np.exp(beta) if apply_exp else ""
exp_ci_lower = np.exp(ci_lower) if apply_exp else ""
exp_ci_upper = np.exp(ci_upper) if apply_exp else ""
if is_log:
table.append([
feature, # Predictor name
beta, # Beta estimate
exp_beta, # Exponential of beta (or blank)
significance_stars(p),
se,
p,
ci_lower,
exp_ci_lower, # Exponential of 95% CI lower bound
ci_upper,
exp_ci_upper # Exponential of 95% CI upper bound
])
else:
table.append([
feature,
beta,
significance_stars(p),
se,
p,
ci_lower,
ci_upper
])
# Process intercept.
if intercept_se is not None:
intercept_p = model.summary.pValues[0] if model.summary.pValues is not None else None
intercept_sig = significance_stars(intercept_p)
ci_intercept_lower = model.intercept - t_critical * intercept_se
ci_intercept_upper = model.intercept + t_critical * intercept_se
else:
intercept_sig = ""
ci_intercept_lower = ""
ci_intercept_upper = ""
intercept_se = ""
if is_log:
table.append([
"Intercept",
model.intercept,
"", # Removed np.exp(model.intercept)
intercept_sig,
intercept_se,
"",
ci_intercept_lower,
"",
ci_intercept_upper,
""
])
else:
table.append([
"Intercept",
model.intercept,
intercept_sig,
intercept_se,
"",
ci_intercept_lower,
ci_intercept_upper
])
# Append overall model metrics.
if is_log:
table.append(["Observations", model.summary.numInstances, "", "", "", "", "", "", "", ""])
table.append(["R²", model.summary.r2, "", "", "", "", "", "", "", ""])
table.append(["RMSE", model.summary.rootMeanSquaredError, "", "", "", "", "", "", "", ""])
else:
table.append(["Observations", model.summary.numInstances, "", "", "", "", ""])
table.append(["R²", model.summary.r2, "", "", "", "", ""])
table.append(["RMSE", model.summary.rootMeanSquaredError, "", "", "", "", ""])
# Format the table rows.
formatted_table = []
for row in table:
formatted_row = []
for i, item in enumerate(row):
# Format Observations as integer with commas.
if row[0] == "Observations" and i == 1 and isinstance(item, (int, float, np.floating)) and item != "":
formatted_row.append(f"{int(item):,}")
elif isinstance(item, (int, float, np.floating)) and item != "":
if is_log:
# When is_log, the columns are:
# 0: Metric, 1: Beta, 2: Exp(Beta), 3: Sig, 4: Std. Error, 5: p-value,
# 6: 95% CI Lower, 7: Exp(95% CI Lower), 8: 95% CI Upper, 9: Exp(95% CI Upper).
if i in [1, 2, 4, 6, 7, 8, 9]:
formatted_row.append(f"{item:,.3f}")
elif i == 5:
formatted_row.append(f"{item:.3f}")
else:
formatted_row.append(f"{item:.3f}")
else:
# When not is_log, the columns are:
# 0: Metric, 1: Beta, 2: Sig, 3: Std. Error, 4: p-value, 5: 95% CI Lower, 6: 95% CI Upper.
if i in [1, 3, 5, 6]:
formatted_row.append(f"{item:,.3f}")
elif i == 4:
formatted_row.append(f"{item:.3f}")
else:
formatted_row.append(f"{item:.3f}")
else:
formatted_row.append(item)
formatted_table.append(formatted_row)
# Set header and column alignment based on whether label starts with "log"
if is_log:
headers = [
f"y: {model.getLabelCol()}",
"Beta", "Exp(Beta)", "Sig.", "Std. Error", "p-value",
"95% CI Lower", "Exp(95% CI Lower)", "95% CI Upper", "Exp(95% CI Upper)"
]
colalign = ("left", "right", "right", "center", "right", "right", "right", "right", "right", "right")
else:
headers = [f"y: {model.getLabelCol()}", "Beta", "Sig.", "Std. Error", "p-value", "95% CI Lower", "95% CI Upper"]
colalign = ("left", "right", "center", "right", "right", "right", "right")
table_str = tabulate(
formatted_table,
headers=headers,
tablefmt="pretty",
colalign=colalign
)
# Insert a dashed line after the Intercept row.
lines = table_str.split("\n")
dash_line = '-' * len(lines[0])
for i, line in enumerate(lines):
if "Intercept" in line and not line.strip().startswith('+'):
lines.insert(i+1, dash_line)
break
return "\n".join(lines)
# Example usage:
# print(regression_table(model_1, assembler_1))add_dummy_variables
Code
def add_dummy_variables(var_name, reference_level, category_order=None):
"""
Creates dummy variables for the specified column in the global DataFrames dtrain and dtest.
Allows manual setting of category order.
Parameters:
var_name (str): The name of the categorical column (e.g., "borough_name").
reference_level (int): Index of the category to be used as the reference (dummy omitted).
category_order (list, optional): List of categories in the desired order. If None, categories are sorted.
Returns:
dummy_cols (list): List of dummy column names excluding the reference category.
ref_category (str): The category chosen as the reference.
"""
global dtrain, dtest
# Get distinct categories from the training set.
categories = dtrain.select(var_name).distinct().rdd.flatMap(lambda x: x).collect()
# Convert booleans to strings if present.
categories = [str(c) if isinstance(c, bool) else c for c in categories]
# Use manual category order if provided; otherwise, sort categories.
if category_order:
# Ensure all categories are present in the user-defined order
missing = set(categories) - set(category_order)
if missing:
raise ValueError(f"These categories are missing from your custom order: {missing}")
categories = category_order
else:
categories = sorted(categories)
# Validate reference_level
if reference_level < 0 or reference_level >= len(categories):
raise ValueError(f"reference_level must be between 0 and {len(categories) - 1}")
# Define the reference category
ref_category = categories[reference_level]
print("Reference category (dummy omitted):", ref_category)
# Create dummy variables for all categories
for cat in categories:
dummy_col_name = var_name + "_" + str(cat).replace(" ", "_")
dtrain = dtrain.withColumn(dummy_col_name, when(col(var_name) == cat, 1).otherwise(0))
dtest = dtest.withColumn(dummy_col_name, when(col(var_name) == cat, 1).otherwise(0))
# List of dummy columns, excluding the reference category
dummy_cols = [var_name + "_" + str(cat).replace(" ", "_") for cat in categories if cat != ref_category]
return dummy_cols, ref_category
# Example usage without category_order:
# dummy_cols_year, ref_category_year = add_dummy_variables('year', 0)
# Example usage with category_order:
# custom_order_wkday = ['sunday', 'monday', 'tuesday', 'wednesday', 'thursday', 'friday', 'saturday']
# dummy_cols_wkday, ref_category_wkday = add_dummy_variables('wkday', reference_level=0, category_order = custom_order_wkday)residual_plot
Code
def residual_plot(df, label_col, model_name):
"""
Generates a residual plot for a given test dataframe.
Parameters:
df (DataFrame): Spark DataFrame containing the test set with predictions.
label_col (str): The column name of the actual outcome variable.
title (str): The title for the residual plot.
Returns:
None (displays the plot)
"""
# Convert to Pandas DataFrame
df_pd = df.select(["prediction", label_col]).toPandas()
df_pd["residual"] = df_pd[label_col] - df_pd["prediction"]
# Scatter plot of residuals vs. predicted values
plt.scatter(df_pd["prediction"], df_pd["residual"], alpha=0.2, color="darkgray")
# Use LOWESS smoothing for trend line
smoothed = sm.nonparametric.lowess(df_pd["residual"], df_pd["prediction"])
plt.plot(smoothed[:, 0], smoothed[:, 1], color="darkblue")
# Add reference line at y=0
plt.axhline(y=0, color="red", linestyle="--")
# Labels and title (model_name)
plt.xlabel("Predicted Values")
plt.ylabel("Residuals")
model_name = "Residual Plot for " + model_name
plt.title(model_name)
# Show plot
plt.show()
# Example usage:
# residual_plot(dtest_1, "log_sales", "Model 1")Data Preparation
Spark DataFrame
# 1. Read CSV data from URL
df_pd = pd.read_csv('https://bcdanl.github.io/data/bikeshare_cleaned.csv')
df = spark.createDataFrame(df_pd)
df.show()+---+----+-----+----+---+--------+-------+-------+--------------------+------------------+-----------------+------------------+
|cnt|year|month|date| hr| wkday|holiday|seasons| weather_cond| temp| hum| windspeed|
+---+----+-----+----+---+--------+-------+-------+--------------------+------------------+-----------------+------------------+
| 16|2011| 1| 1| 0|saturday| 0| spring| Clear or Few Cloudy| -1.33460918694128|0.947345243330896| -1.5538438052971|
| 40|2011| 1| 1| 1|saturday| 0| spring| Clear or Few Cloudy| -1.43847500990342|0.895512927978679| -1.5538438052971|
| 32|2011| 1| 1| 2|saturday| 0| spring| Clear or Few Cloudy| -1.43847500990342|0.895512927978679| -1.5538438052971|
| 13|2011| 1| 1| 3|saturday| 0| spring| Clear or Few Cloudy| -1.33460918694128|0.636351351217591| -1.5538438052971|
| 1|2011| 1| 1| 4|saturday| 0| spring| Clear or Few Cloudy| -1.33460918694128|0.636351351217591| -1.5538438052971|
| 1|2011| 1| 1| 5|saturday| 0| spring| Mist or Cloudy| -1.33460918694128|0.636351351217591|-0.821460017517193|
| 2|2011| 1| 1| 6|saturday| 0| spring| Clear or Few Cloudy| -1.43847500990342|0.895512927978679| -1.5538438052971|
| 3|2011| 1| 1| 7|saturday| 0| spring| Clear or Few Cloudy| -1.54234083286556| 1.20650682009198| -1.5538438052971|
| 8|2011| 1| 1| 8|saturday| 0| spring| Clear or Few Cloudy| -1.33460918694128|0.636351351217591| -1.5538438052971|
| 14|2011| 1| 1| 9|saturday| 0| spring| Clear or Few Cloudy|-0.919145895092722|0.688183666569809| -1.5538438052971|
| 36|2011| 1| 1| 10|saturday| 0| spring| Clear or Few Cloudy|-0.607548426206302|0.688183666569809| 0.519881272378821|
| 56|2011| 1| 1| 11|saturday| 0| spring| Clear or Few Cloudy|-0.711414249168442|0.947345243330896| 0.764281665845554|
| 84|2011| 1| 1| 12|saturday| 0| spring| Clear or Few Cloudy|-0.399816780282022|0.740015981922026| 0.764281665845554|
| 94|2011| 1| 1| 13|saturday| 0| spring| Mist or Cloudy|-0.192085134357741|0.480854405160939| 0.886073166268775|
|106|2011| 1| 1| 14|saturday| 0| spring| Mist or Cloudy|-0.192085134357741|0.480854405160939| 0.764281665845554|
|110|2011| 1| 1| 15|saturday| 0| spring| Mist or Cloudy|-0.295950957319881|0.740015981922026| 0.886073166268775|
| 93|2011| 1| 1| 16|saturday| 0| spring| Mist or Cloudy|-0.399816780282022|0.999177558683113| 0.886073166268775|
| 67|2011| 1| 1| 17|saturday| 0| spring| Mist or Cloudy|-0.295950957319881|0.999177558683113| 0.764281665845554|
| 35|2011| 1| 1| 18|saturday| 0| spring|Light Snow or Lig...|-0.399816780282022| 1.31017145079642| 0.519881272378821|
| 37|2011| 1| 1| 19|saturday| 0| spring|Light Snow or Lig...|-0.399816780282022| 1.31017145079642| 0.519881272378821|
+---+----+-----+----+---+--------+-------+-------+--------------------+------------------+-----------------+------------------+
only showing top 20 rows
Training-Test Split
dtrain, dtest = df.randomSplit([0.6, 0.4], seed = 1234)Adding Dummies
dummy_cols_year, ref_category_year = add_dummy_variables('year', 0)
dummy_cols_month, ref_category_month = add_dummy_variables('month', 0)
dummy_cols_hr, ref_category_hr = add_dummy_variables('hr', 0)
custom_order_wkday = ['sunday', 'monday', 'tuesday', 'wednesday', 'thursday', 'friday', 'saturday'] # Custom category_order
dummy_cols_wkday, ref_category_wkday = add_dummy_variables('wkday', reference_level=0, category_order = custom_order_wkday)
dummy_cols_holiday, ref_category_holiday = add_dummy_variables('holiday', 0)
custom_order_seasons = ['spring', 'summer', 'fall', 'winter'] # Custom category_order
dummy_cols_seasons, ref_category_seasons = add_dummy_variables('seasons', 0, custom_order_seasons)
dummy_cols_weather_cond, ref_category_weather_cond = add_dummy_variables('weather_cond', 0)Reference category (dummy omitted): 2011
Reference category (dummy omitted): 1
Reference category (dummy omitted): 0
Reference category (dummy omitted): sunday
Reference category (dummy omitted): 0
Reference category (dummy omitted): spring
Reference category (dummy omitted): Clear or Few CloudyModel
Assembling Predictors
conti_cols = ["temp", "hum", "windspeed"]
assembler_predictors = (
conti_cols +
dummy_cols_year + dummy_cols_month +
dummy_cols_hr + dummy_cols_wkday +
dummy_cols_holiday + dummy_cols_seasons + dummy_cols_weather_cond
)
assembler_dum = VectorAssembler(
inputCols = assembler_predictors,
outputCol = "predictors"
)
dtrain_dum = assembler_dum.transform(dtrain)
dtest_dum = assembler_dum.transform(dtest)Fitting Regression
model_dum = (
LinearRegression(featuresCol="predictors",
labelCol="cnt")
.fit(dtrain_dum)
)Regression Table
print( regression_table(model_dum, assembler_dum) )+---------------------------------------+---------+------+------------+---------+--------------+--------------+
| y: cnt | Beta | Sig. | Std. Error | p-value | 95% CI Lower | 95% CI Upper |
+---------------------------------------+---------+------+------------+---------+--------------+--------------+
| temp | 45.307 | *** | 1.395 | 0.000 | 42.573 | 48.042 |
| hum | -17.193 | *** | 1.095 | 0.000 | -19.339 | -15.046 |
| windspeed | -4.617 | *** | 2.029 | 0.000 | -8.595 | -0.639 |
| year_2012 | 85.361 | *** | 5.129 | 0.000 | 75.308 | 95.414 |
| month_2 | 8.508 | * | 5.765 | 0.097 | -2.792 | 19.809 |
| month_3 | 18.322 | *** | 8.557 | 0.001 | 1.550 | 35.095 |
| month_4 | 10.784 | | 9.177 | 0.208 | -7.205 | 28.772 |
| month_5 | 25.990 | *** | 9.402 | 0.005 | 7.561 | 44.420 |
| month_6 | 4.947 | | 10.543 | 0.599 | -15.720 | 25.613 |
| month_7 | -10.677 | | 10.250 | 0.311 | -30.768 | 9.415 |
| month_8 | 10.144 | | 9.119 | 0.322 | -7.732 | 28.020 |
| month_9 | 34.887 | *** | 8.440 | 0.000 | 18.343 | 51.432 |
| month_10 | 18.646 | ** | 8.105 | 0.027 | 2.758 | 34.534 |
| month_11 | -6.450 | | 6.482 | 0.426 | -19.155 | 6.256 |
| month_12 | -5.341 | | 6.938 | 0.410 | -18.940 | 8.258 |
| hr_1 | -19.935 | *** | 6.964 | 0.004 | -33.585 | -6.285 |
| hr_2 | -26.234 | *** | 6.986 | 0.000 | -39.929 | -12.540 |
| hr_3 | -40.899 | *** | 6.919 | 0.000 | -54.461 | -27.336 |
| hr_4 | -41.142 | *** | 6.974 | 0.000 | -54.813 | -27.472 |
| hr_5 | -24.888 | *** | 6.922 | 0.000 | -38.456 | -11.321 |
| hr_6 | 31.898 | *** | 6.991 | 0.000 | 18.194 | 45.601 |
| hr_7 | 166.868 | *** | 6.959 | 0.000 | 153.228 | 180.508 |
| hr_8 | 294.758 | *** | 6.915 | 0.000 | 281.203 | 308.312 |
| hr_9 | 163.694 | *** | 6.967 | 0.000 | 150.037 | 177.351 |
| hr_10 | 109.802 | *** | 7.056 | 0.000 | 95.971 | 123.634 |
| hr_11 | 134.459 | *** | 7.085 | 0.000 | 120.571 | 148.347 |
| hr_12 | 176.590 | *** | 7.132 | 0.000 | 162.609 | 190.570 |
| hr_13 | 166.123 | *** | 7.152 | 0.000 | 152.105 | 180.142 |
| hr_14 | 151.832 | *** | 7.053 | 0.000 | 138.006 | 165.657 |
| hr_15 | 160.555 | *** | 7.208 | 0.000 | 146.427 | 174.683 |
| hr_16 | 224.717 | *** | 7.129 | 0.000 | 210.742 | 238.691 |
| hr_17 | 378.531 | *** | 7.007 | 0.000 | 364.796 | 392.265 |
| hr_18 | 339.843 | *** | 6.962 | 0.000 | 326.196 | 353.490 |
| hr_19 | 233.479 | *** | 6.963 | 0.000 | 219.830 | 247.127 |
| hr_20 | 156.485 | *** | 6.922 | 0.000 | 142.917 | 170.053 |
| hr_21 | 109.363 | *** | 6.866 | 0.000 | 95.904 | 122.821 |
| hr_22 | 69.689 | *** | 6.903 | 0.000 | 56.157 | 83.220 |
| hr_23 | 29.770 | *** | 3.861 | 0.000 | 22.201 | 37.339 |
| wkday_monday | 11.570 | *** | 3.760 | 0.003 | 4.200 | 18.940 |
| wkday_tuesday | 11.127 | *** | 3.798 | 0.003 | 3.682 | 18.571 |
| wkday_wednesday | 11.043 | *** | 3.770 | 0.004 | 3.653 | 18.433 |
| wkday_thursday | 15.072 | *** | 3.757 | 0.000 | 7.707 | 22.437 |
| wkday_friday | 18.413 | *** | 3.757 | 0.000 | 11.048 | 25.778 |
| wkday_saturday | 22.575 | *** | 6.324 | 0.000 | 10.179 | 34.971 |
| holiday_1 | -27.635 | *** | 6.360 | 0.000 | -40.102 | -15.169 |
| seasons_summer | 37.101 | *** | 7.501 | 0.000 | 22.398 | 51.803 |
| seasons_fall | 32.195 | *** | 6.345 | 0.000 | 19.758 | 44.631 |
| seasons_winter | 68.404 | *** | 4.235 | 0.000 | 60.102 | 76.706 |
| weather_cond_Light_Snow_or_Light_Rain | -57.274 | *** | 2.495 | 0.000 | -62.166 | -52.383 |
| weather_cond_Mist_or_Cloudy | -10.256 | *** | 7.526 | 0.000 | -25.008 | 4.496 |
| Intercept | -25.277 | *** | 2.362 | 0.000 | -29.906 | -20.648 |
---------------------------------------------------------------------------------------------------------------
| Observations | 10,431 | | | | | |
| R² | 0.685 | | | | | |
| RMSE | 102.177 | | | | | |
+---------------------------------------+---------+------+------------+---------+--------------+--------------+Making Predictions
dtest_dum = model_dum.transform(dtest_dum)Coefficient Plots
Pandas DataFrame for the Plots
terms = assembler_dum.getInputCols()
coefs = model_dum.coefficients.toArray()[:len(terms)]
stdErrs = model_dum.summary.coefficientStandardErrors[:len(terms)]
df_summary = pd.DataFrame({
"term": terms,
"estimate": coefs,
"std_error": stdErrs
})temp, hum and windspeed variables.
# Filter df_summary if needed
cond = df_summary['term'].isin(['temp', 'hum', 'windspeed'])
df_summary_1 = df_summary[cond]
# Plot using the DataFrame columns
plt.errorbar(df_summary_1["term"], df_summary_1["estimate"],
yerr = 1.96 * df_summary_1["std_error"], fmt='o', capsize=5)
plt.xlabel("Terms")
plt.ylabel("Coefficient Estimate")
plt.title("Coefficient Estimates")
plt.axhline(0, color="red", linestyle="--") # Add horizontal line at 0
plt.xticks(rotation=45)
plt.show()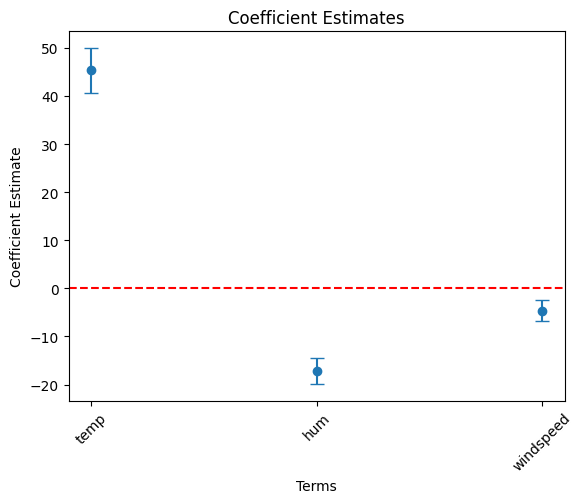
month variables.
# Filter df_summary if needed
month_list = ['month_' + str(i) for i in range(2, 13)]
cond = df_summary['term'].isin( month_list )
df_summary_2 = df_summary[cond]
# Plot using the DataFrame columns
plt.errorbar(df_summary_2["term"], df_summary_2["estimate"],
yerr = 1.96 * df_summary_2["std_error"], fmt='o', capsize=5)
plt.xlabel("Terms")
plt.ylabel("Coefficient Estimate")
plt.title("Coefficient Estimates")
plt.axhline(0, color="red", linestyle="--") # Add horizontal line at 0
plt.xticks(rotation=45)
plt.show()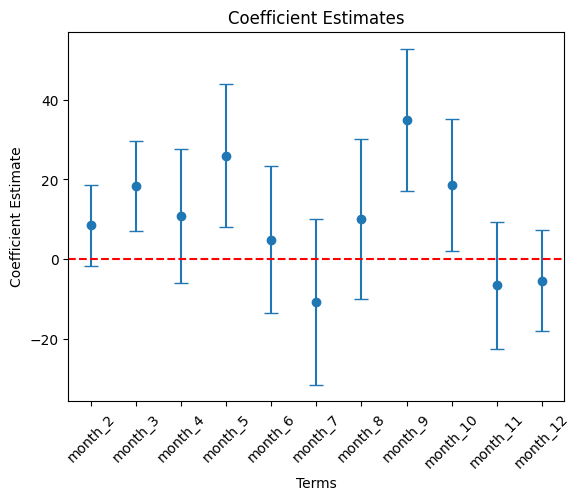
hr variables
# Filter df_summary if needed
hr_list = ['hr_' + str(i) for i in range(1, 25)]
cond = df_summary['term'].isin( hr_list )
df_summary_3 = df_summary[cond]
# Plot using the DataFrame columns
plt.errorbar(df_summary_3["term"], df_summary_3["estimate"],
yerr = 1.96 * df_summary_3["std_error"], fmt='o', capsize=5)
plt.xlabel("Terms")
plt.ylabel("Coefficient Estimate")
plt.title("Coefficient Estimates")
plt.axhline(0, color="red", linestyle="--") # Add horizontal line at 0
plt.xticks(rotation=45)
plt.show()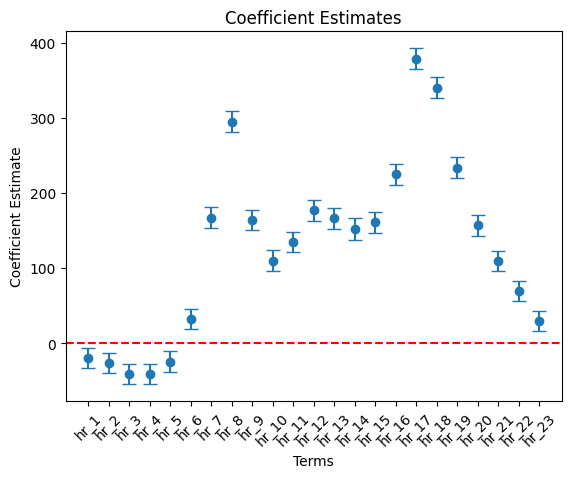
wkday variables
# Filter df_summary if needed
wkday_list = [ 'wkday_' + day for day in ['monday', 'tuesday', 'wednesday', 'thursday', 'friday', 'saturday'] ]
cond = df_summary['term'].isin( wkday_list )
df_summary_4 = df_summary[cond]
# Plot using the DataFrame columns
plt.errorbar(df_summary_4["term"], df_summary_4["estimate"],
yerr = 1.96 * df_summary_4["std_error"], fmt='o', capsize=5)
plt.xlabel("Terms")
plt.ylabel("Coefficient Estimate")
plt.title("Coefficient Estimates")
plt.axhline(0, color="red", linestyle="--") # Add horizontal line at 0
plt.xticks(rotation=45)
plt.show()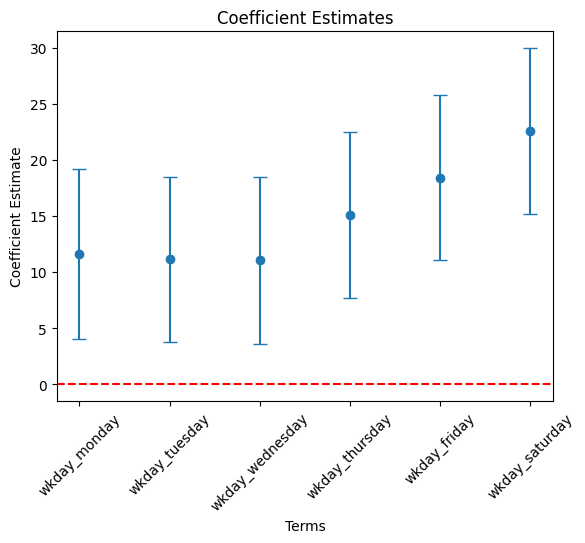
- Draw a coefficient plot for seasons variables.
# Filter df_summary if needed
seasons_list = [ 'seasons_' + s for s in ['summer', 'fall', 'winter'] ]
cond = df_summary['term'].isin( seasons_list )
df_summary_5 = df_summary[cond]
# Plot using the DataFrame columns
plt.errorbar(df_summary_5["term"], df_summary_5["estimate"],
yerr = 1.96 * df_summary_5["std_error"], fmt='o', capsize=5)
plt.xlabel("Terms")
plt.ylabel("Coefficient Estimate")
plt.title("Coefficient Estimates")
plt.axhline(0, color="red", linestyle="--") # Add horizontal line at 0
plt.xticks(rotation=45)
plt.show()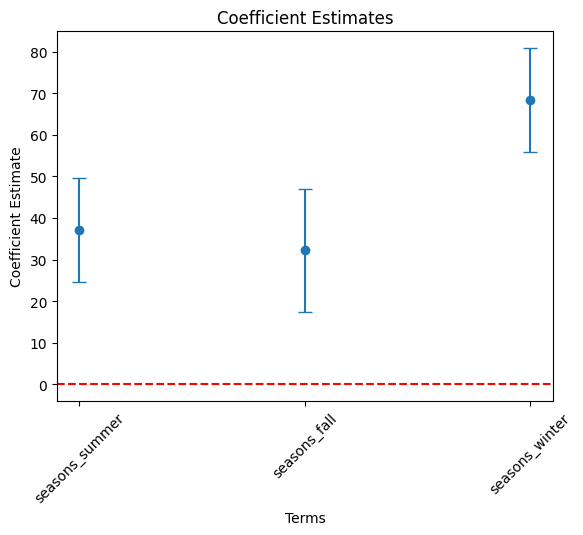
- Draw a coefficient plot for weather_cond variables.
# Filter df_summary if needed
weather_cond_list = [ 'weather_cond_' + s for s in ['Light_Snow_or_Light_Rain', 'Mist_or_Cloudy'] ]
cond = df_summary['term'].isin( weather_cond_list )
df_summary_6 = df_summary[cond]
# Plot using the DataFrame columns
plt.errorbar(df_summary_6["term"], df_summary_6["estimate"],
yerr = 1.96 * df_summary_6["std_error"], fmt='o', capsize=5)
plt.xlabel("Terms")
plt.ylabel("Coefficient Estimate")
plt.title("Coefficient Estimates")
plt.axhline(0, color="red", linestyle="--") # Add horizontal line at 0
plt.xticks(rotation=45)
plt.show()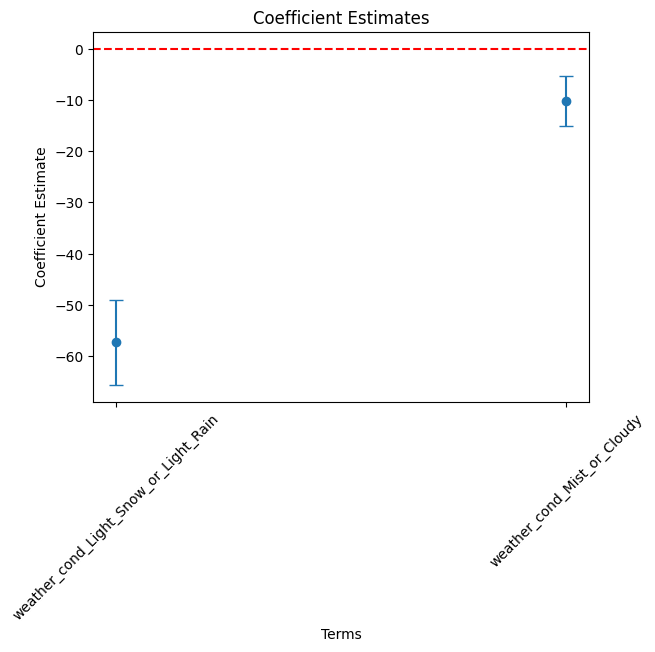
Residual Plot
residual_plot(dtest_dum, "cnt", "the Model")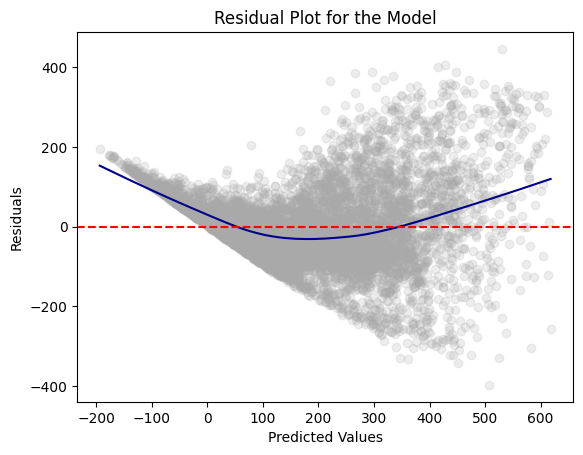
RMSE
dtest_dum = dtest_dum.withColumn("error_sq", pow(col('cnt') - col('prediction'), 2))
rmse_dum = dtest_dum.agg(sqrt(avg("error_sq")).alias("rmse")).collect()[0]["rmse"]
rmse_dum101.18558392860682Log of cnt
df = df.withColumn("log_cnt", log( df['cnt'] ) )
df.show()+---+----+-----+----+---+--------+-------+-------+--------------------+------------------+-----------------+------------------+------------------+
|cnt|year|month|date| hr| wkday|holiday|seasons| weather_cond| temp| hum| windspeed| log_cnt|
+---+----+-----+----+---+--------+-------+-------+--------------------+------------------+-----------------+------------------+------------------+
| 16|2011| 1| 1| 0|saturday| 0| spring| Clear or Few Cloudy| -1.33460918694128|0.947345243330896| -1.5538438052971| 2.772588722239781|
| 40|2011| 1| 1| 1|saturday| 0| spring| Clear or Few Cloudy| -1.43847500990342|0.895512927978679| -1.5538438052971|3.6888794541139363|
| 32|2011| 1| 1| 2|saturday| 0| spring| Clear or Few Cloudy| -1.43847500990342|0.895512927978679| -1.5538438052971|3.4657359027997265|
| 13|2011| 1| 1| 3|saturday| 0| spring| Clear or Few Cloudy| -1.33460918694128|0.636351351217591| -1.5538438052971|2.5649493574615367|
| 1|2011| 1| 1| 4|saturday| 0| spring| Clear or Few Cloudy| -1.33460918694128|0.636351351217591| -1.5538438052971| 0.0|
| 1|2011| 1| 1| 5|saturday| 0| spring| Mist or Cloudy| -1.33460918694128|0.636351351217591|-0.821460017517193| 0.0|
| 2|2011| 1| 1| 6|saturday| 0| spring| Clear or Few Cloudy| -1.43847500990342|0.895512927978679| -1.5538438052971|0.6931471805599453|
| 3|2011| 1| 1| 7|saturday| 0| spring| Clear or Few Cloudy| -1.54234083286556| 1.20650682009198| -1.5538438052971|1.0986122886681096|
| 8|2011| 1| 1| 8|saturday| 0| spring| Clear or Few Cloudy| -1.33460918694128|0.636351351217591| -1.5538438052971|2.0794415416798357|
| 14|2011| 1| 1| 9|saturday| 0| spring| Clear or Few Cloudy|-0.919145895092722|0.688183666569809| -1.5538438052971|2.6390573296152584|
| 36|2011| 1| 1| 10|saturday| 0| spring| Clear or Few Cloudy|-0.607548426206302|0.688183666569809| 0.519881272378821| 3.58351893845611|
| 56|2011| 1| 1| 11|saturday| 0| spring| Clear or Few Cloudy|-0.711414249168442|0.947345243330896| 0.764281665845554| 4.02535169073515|
| 84|2011| 1| 1| 12|saturday| 0| spring| Clear or Few Cloudy|-0.399816780282022|0.740015981922026| 0.764281665845554| 4.430816798843313|
| 94|2011| 1| 1| 13|saturday| 0| spring| Mist or Cloudy|-0.192085134357741|0.480854405160939| 0.886073166268775| 4.543294782270004|
|106|2011| 1| 1| 14|saturday| 0| spring| Mist or Cloudy|-0.192085134357741|0.480854405160939| 0.764281665845554| 4.663439094112067|
|110|2011| 1| 1| 15|saturday| 0| spring| Mist or Cloudy|-0.295950957319881|0.740015981922026| 0.886073166268775| 4.700480365792417|
| 93|2011| 1| 1| 16|saturday| 0| spring| Mist or Cloudy|-0.399816780282022|0.999177558683113| 0.886073166268775| 4.532599493153256|
| 67|2011| 1| 1| 17|saturday| 0| spring| Mist or Cloudy|-0.295950957319881|0.999177558683113| 0.764281665845554| 4.204692619390966|
| 35|2011| 1| 1| 18|saturday| 0| spring|Light Snow or Lig...|-0.399816780282022| 1.31017145079642| 0.519881272378821|3.5553480614894135|
| 37|2011| 1| 1| 19|saturday| 0| spring|Light Snow or Lig...|-0.399816780282022| 1.31017145079642| 0.519881272378821|3.6109179126442243|
+---+----+-----+----+---+--------+-------+-------+--------------------+------------------+-----------------+------------------+------------------+
only showing top 20 rows
Histograms
cnt
# Create a histogram
dfpd = df.select(["cnt"]).toPandas()
sns.histplot(dfpd["cnt"], bins=10, kde=True)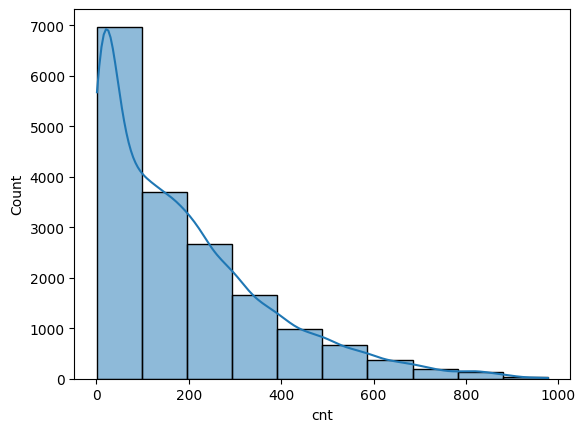
log_cnt
# Create a histogram
dfpd = df.select(["log_cnt"]).toPandas()
sns.histplot(dfpd["log_cnt"], bins=10, kde=True)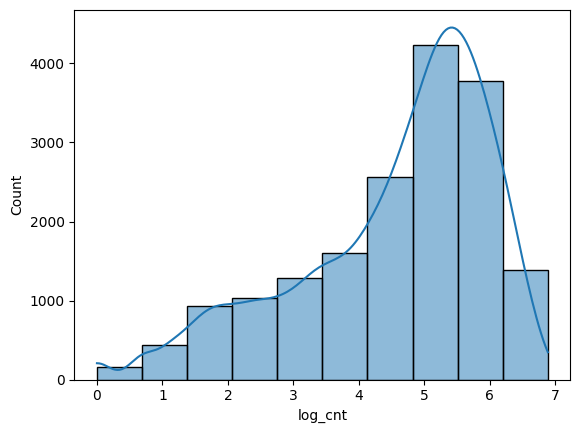
Model with Log-Outcome Variable
Data Preparation
Training-Test Split
dtrain, dtest = df.randomSplit([0.6, 0.4], seed = 1234)Adding Dummies
dummy_cols_year, ref_category_year = add_dummy_variables('year', 0)
dummy_cols_month, ref_category_month = add_dummy_variables('month', 0)
dummy_cols_hr, ref_category_hr = add_dummy_variables('hr', 0)
custom_order_wkday = ['sunday', 'monday', 'tuesday', 'wednesday', 'thursday', 'friday', 'saturday'] # Custom category_order
dummy_cols_wkday, ref_category_wkday = add_dummy_variables('wkday', reference_level=0, category_order = custom_order_wkday)
dummy_cols_holiday, ref_category_holiday = add_dummy_variables('holiday', 0)
custom_order_seasons = ['spring', 'summer', 'fall', 'winter'] # Custom category_order
dummy_cols_seasons, ref_category_seasons = add_dummy_variables('seasons', 0, custom_order_seasons)
dummy_cols_weather_cond, ref_category_weather_cond = add_dummy_variables('weather_cond', 0)Reference category (dummy omitted): 2011
Reference category (dummy omitted): 1
Reference category (dummy omitted): 0
Reference category (dummy omitted): sunday
Reference category (dummy omitted): 0
Reference category (dummy omitted): spring
Reference category (dummy omitted): Clear or Few CloudyAssembling Predictors
conti_cols = ["temp", "hum", "windspeed"]
assembler_predictors = (
conti_cols +
dummy_cols_year + dummy_cols_month +
dummy_cols_hr + dummy_cols_wkday +
dummy_cols_holiday + dummy_cols_seasons + dummy_cols_weather_cond
)
assembler_log = VectorAssembler(
inputCols = assembler_predictors,
outputCol = "predictors"
)
dtrain_log = assembler_log.transform(dtrain)
dtest_log = assembler_log.transform(dtest)Fitting Regression
model_log = (
LinearRegression(featuresCol="predictors",
labelCol="log_cnt")
.fit(dtrain_log)
)Regression Table
print( regression_table(model_log, assembler_log) )+---------------------------------------+--------+-----------+------+------------+---------+--------------+-------------------+--------------+-------------------+
| y: log_cnt | Beta | Exp(Beta) | Sig. | Std. Error | p-value | 95% CI Lower | Exp(95% CI Lower) | 95% CI Upper | Exp(95% CI Upper) |
+---------------------------------------+--------+-----------+------+------------+---------+--------------+-------------------+--------------+-------------------+
| temp | 0.271 | 1.311 | *** | 0.008 | 0.000 | 0.254 | 1.290 | 0.288 | 1.333 |
| hum | -0.056 | 0.946 | *** | 0.007 | 0.000 | -0.069 | 0.933 | -0.043 | 0.958 |
| windspeed | -0.028 | 0.972 | *** | 0.012 | 0.000 | -0.053 | 0.949 | -0.004 | 0.996 |
| year_2012 | 0.463 | 1.589 | *** | 0.031 | 0.000 | 0.402 | 1.494 | 0.524 | 1.689 |
| month_2 | 0.146 | 1.157 | *** | 0.035 | 0.000 | 0.077 | 1.080 | 0.214 | 1.239 |
| month_3 | 0.208 | 1.231 | *** | 0.052 | 0.000 | 0.106 | 1.112 | 0.310 | 1.364 |
| month_4 | 0.177 | 1.194 | *** | 0.056 | 0.001 | 0.068 | 1.070 | 0.287 | 1.332 |
| month_5 | 0.314 | 1.369 | *** | 0.057 | 0.000 | 0.202 | 1.224 | 0.426 | 1.532 |
| month_6 | 0.188 | 1.207 | *** | 0.064 | 0.001 | 0.063 | 1.065 | 0.314 | 1.369 |
| month_7 | 0.046 | 1.047 | | 0.062 | 0.478 | -0.077 | 0.926 | 0.168 | 1.183 |
| month_8 | 0.123 | 1.131 | ** | 0.056 | 0.049 | 0.014 | 1.014 | 0.232 | 1.261 |
| month_9 | 0.204 | 1.227 | *** | 0.051 | 0.000 | 0.104 | 1.109 | 0.305 | 1.357 |
| month_10 | 0.085 | 1.088 | * | 0.049 | 0.100 | -0.012 | 0.988 | 0.181 | 1.199 |
| month_11 | -0.015 | 0.985 | | 0.039 | 0.765 | -0.092 | 0.912 | 0.063 | 1.065 |
| month_12 | -0.022 | 0.978 | | 0.042 | 0.574 | -0.105 | 0.900 | 0.061 | 1.062 |
| hr_1 | -0.642 | 0.526 | *** | 0.042 | 0.000 | -0.725 | 0.484 | -0.559 | 0.572 |
| hr_2 | -1.247 | 0.287 | *** | 0.043 | 0.000 | -1.331 | 0.264 | -1.164 | 0.312 |
| hr_3 | -1.776 | 0.169 | *** | 0.042 | 0.000 | -1.858 | 0.156 | -1.693 | 0.184 |
| hr_4 | -2.057 | 0.128 | *** | 0.042 | 0.000 | -2.140 | 0.118 | -1.974 | 0.139 |
| hr_5 | -0.934 | 0.393 | *** | 0.042 | 0.000 | -1.017 | 0.362 | -0.852 | 0.427 |
| hr_6 | 0.232 | 1.261 | *** | 0.043 | 0.000 | 0.149 | 1.160 | 0.315 | 1.371 |
| hr_7 | 1.216 | 3.375 | *** | 0.042 | 0.000 | 1.133 | 3.106 | 1.299 | 3.667 |
| hr_8 | 1.807 | 6.090 | *** | 0.042 | 0.000 | 1.724 | 5.607 | 1.889 | 6.614 |
| hr_9 | 1.560 | 4.760 | *** | 0.042 | 0.000 | 1.477 | 4.380 | 1.643 | 5.173 |
| hr_10 | 1.234 | 3.436 | *** | 0.043 | 0.000 | 1.150 | 3.159 | 1.319 | 3.738 |
| hr_11 | 1.330 | 3.780 | *** | 0.043 | 0.000 | 1.245 | 3.473 | 1.414 | 4.113 |
| hr_12 | 1.532 | 4.628 | *** | 0.043 | 0.000 | 1.447 | 4.250 | 1.617 | 5.039 |
| hr_13 | 1.494 | 4.454 | *** | 0.044 | 0.000 | 1.408 | 4.090 | 1.579 | 4.851 |
| hr_14 | 1.433 | 4.191 | *** | 0.043 | 0.000 | 1.349 | 3.853 | 1.517 | 4.560 |
| hr_15 | 1.462 | 4.315 | *** | 0.044 | 0.000 | 1.376 | 3.959 | 1.548 | 4.702 |
| hr_16 | 1.728 | 5.627 | *** | 0.043 | 0.000 | 1.642 | 5.168 | 1.813 | 6.127 |
| hr_17 | 2.116 | 8.302 | *** | 0.043 | 0.000 | 2.033 | 7.636 | 2.200 | 9.026 |
| hr_18 | 2.026 | 7.580 | *** | 0.042 | 0.000 | 1.942 | 6.976 | 2.109 | 8.237 |
| hr_19 | 1.763 | 5.827 | *** | 0.042 | 0.000 | 1.679 | 5.363 | 1.846 | 6.332 |
| hr_20 | 1.461 | 4.311 | *** | 0.042 | 0.000 | 1.379 | 3.969 | 1.544 | 4.682 |
| hr_21 | 1.222 | 3.395 | *** | 0.042 | 0.000 | 1.140 | 3.128 | 1.304 | 3.685 |
| hr_22 | 0.952 | 2.590 | *** | 0.042 | 0.000 | 0.869 | 2.385 | 1.034 | 2.812 |
| hr_23 | 0.536 | 1.709 | *** | 0.024 | 0.000 | 0.490 | 1.632 | 0.582 | 1.790 |
| wkday_monday | -0.024 | 0.977 | | 0.023 | 0.317 | -0.068 | 0.934 | 0.021 | 1.022 |
| wkday_tuesday | -0.032 | 0.969 | | 0.023 | 0.165 | -0.077 | 0.926 | 0.014 | 1.014 |
| wkday_wednesday | -0.028 | 0.973 | | 0.023 | 0.234 | -0.073 | 0.930 | 0.017 | 1.018 |
| wkday_thursday | 0.026 | 1.026 | | 0.023 | 0.262 | -0.019 | 0.981 | 0.071 | 1.073 |
| wkday_friday | 0.134 | 1.143 | *** | 0.023 | 0.000 | 0.089 | 1.093 | 0.179 | 1.196 |
| wkday_saturday | 0.145 | 1.156 | *** | 0.039 | 0.000 | 0.069 | 1.072 | 0.220 | 1.247 |
| holiday_1 | -0.146 | 0.865 | *** | 0.039 | 0.000 | -0.221 | 0.801 | -0.070 | 0.933 |
| seasons_summer | 0.277 | 1.320 | *** | 0.046 | 0.000 | 0.188 | 1.207 | 0.367 | 1.443 |
| seasons_fall | 0.342 | 1.407 | *** | 0.039 | 0.000 | 0.266 | 1.305 | 0.417 | 1.518 |
| seasons_winter | 0.618 | 1.855 | *** | 0.026 | 0.000 | 0.567 | 1.764 | 0.669 | 1.951 |
| weather_cond_Light_Snow_or_Light_Rain | -0.548 | 0.578 | *** | 0.015 | 0.000 | -0.578 | 0.561 | -0.518 | 0.596 |
| weather_cond_Mist_or_Cloudy | -0.042 | 0.959 | *** | 0.046 | 0.005 | -0.132 | 0.876 | 0.048 | 1.049 |
| Intercept | 3.117 | | *** | 0.014 | | 3.088 | | 3.145 | |
------------------------------------------------------------------------------------------------------------------------------------------------------------------
| Observations | 10,431 | | | | | | | | |
| R² | 0.826 | | | | | | | | |
| RMSE | 0.622 | | | | | | | | |
+---------------------------------------+--------+-----------+------+------------+---------+--------------+-------------------+--------------+-------------------+Making Predictions
dtest_log = model_log.transform(dtest_log)Coefficient Plots
Pandas DataFrame for the Plots
terms = assembler_log.getInputCols()
coefs = model_log.coefficients.toArray()[:len(terms)]
stdErrs = model_log.summary.coefficientStandardErrors[:len(terms)]
df_summary = pd.DataFrame({
"term": terms,
"estimate": coefs,
"std_error": stdErrs
})temp, hum and windspeed variables.
# Filter df_summary if needed
cond = df_summary['term'].isin(['temp', 'hum', 'windspeed'])
df_summary_1 = df_summary[cond]
# Plot using the DataFrame columns
plt.errorbar(df_summary_1["term"],
df_summary_1["estimate"],
yerr = 1.96 * df_summary_1["std_error"], fmt='o', capsize=5)
plt.xlabel("Terms")
plt.ylabel("Coefficient Estimate")
plt.title("Coefficient Estimates")
plt.axhline(0, color="red", linestyle="--") # Add horizontal line at 0
plt.xticks(rotation=45)
plt.show()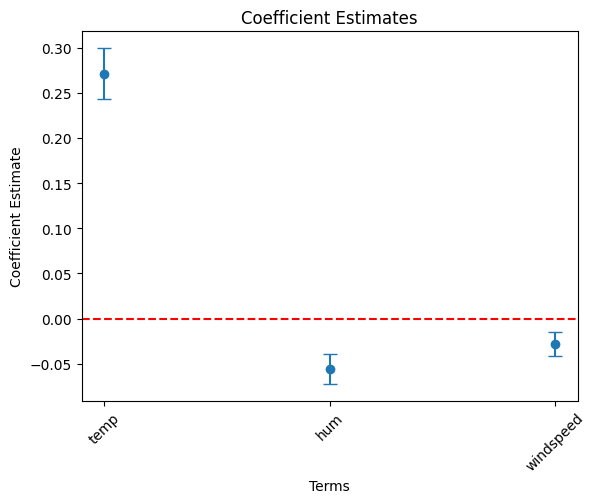
month variables.
# Filter df_summary if needed
month_list = ['month_' + str(i) for i in range(2, 13)]
cond = df_summary['term'].isin( month_list )
df_summary_2 = df_summary[cond]
# Plot using the DataFrame columns
plt.errorbar(df_summary_2["term"], df_summary_2["estimate"],
yerr = 1.96 * df_summary_2["std_error"], fmt='o', capsize=5)
plt.xlabel("Terms")
plt.ylabel("Coefficient Estimate")
plt.title("Coefficient Estimates")
plt.axhline(0, color="red", linestyle="--") # Add horizontal line at 0
plt.xticks(rotation=45)
plt.show()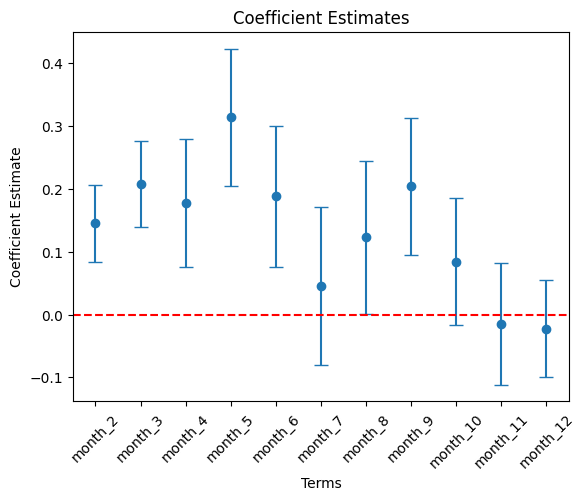
hr variables
# Filter df_summary if needed
hr_list = ['hr_' + str(i) for i in range(1, 25)]
cond = df_summary['term'].isin( hr_list )
df_summary_3 = df_summary[cond]
# Plot using the DataFrame columns
plt.errorbar(df_summary_3["term"], df_summary_3["estimate"],
yerr = 1.96 * df_summary_3["std_error"], fmt='o', capsize=5)
plt.xlabel("Terms")
plt.ylabel("Coefficient Estimate")
plt.title("Coefficient Estimates")
plt.axhline(0, color="red", linestyle="--") # Add horizontal line at 0
plt.xticks(rotation=45)
plt.show()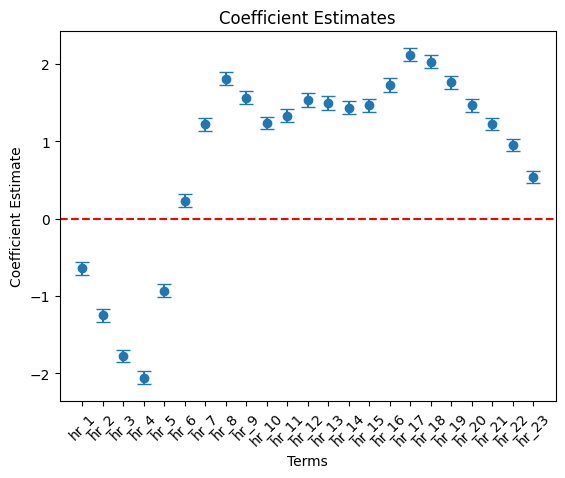
wkday variables
# Filter df_summary if needed
wkday_list = [ 'wkday_' + day for day in ['monday', 'tuesday', 'wednesday', 'thursday', 'friday', 'saturday'] ]
cond = df_summary['term'].isin( wkday_list )
df_summary_4 = df_summary[cond]
# Plot using the DataFrame columns
plt.errorbar(df_summary_4["term"], df_summary_4["estimate"],
yerr = 1.96 * df_summary_4["std_error"], fmt='o', capsize=5)
plt.xlabel("Terms")
plt.ylabel("Coefficient Estimate")
plt.title("Coefficient Estimates")
plt.axhline(0, color="red", linestyle="--") # Add horizontal line at 0
plt.xticks(rotation=45)
plt.show()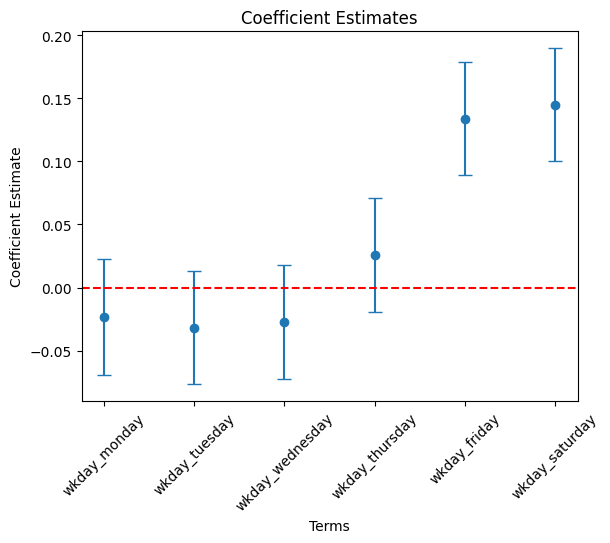
Residual Plot
residual_plot(dtest_log, "log_cnt", "the Model")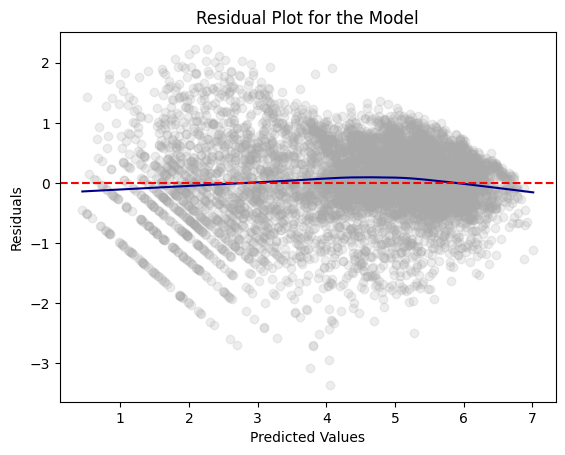
RMSE
dtest_log = dtest_log.withColumn("error_sq", pow(col('log_cnt') - col('prediction'), 2))
rmse_log = dtest_log.agg(sqrt(avg("error_sq")).alias("rmse")).collect()[0]["rmse"]
rmse_log0.6288655799916469# transform fitted log_cnt to fitted cnt
dtest_log = dtest_log.withColumn("prediction_cnt", exp(col('prediction')))dtest_log = dtest_log.withColumn("error_sq_transform", pow(col('cnt') - col('prediction_cnt'), 2))
rmse_log = dtest_log.agg(sqrt(avg("error_sq_transform")).alias("rmse")).collect()[0]["rmse"]
rmse_log98.60168448259316