Lecture 6
Tree-based Model II: Ensemble Models
March 30, 2026
Bootstrap
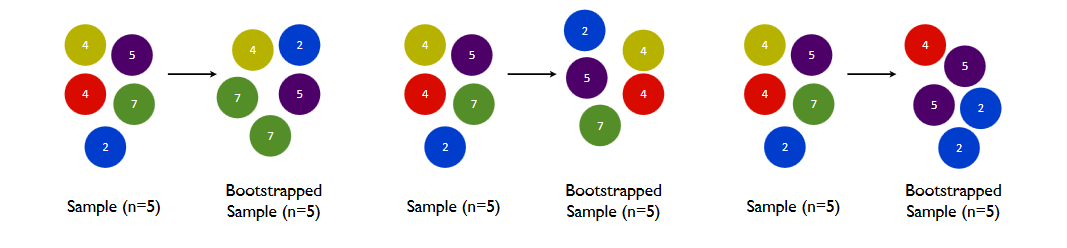
- Bootstrap is random sampling with replacement.
- “With replacement” means the same observation can be drawn more than once into a single bootstrap sample.
- On average, each bootstrap sample contains about 63% of the unique original observations — the rest are left out.
- Bootstrap is a reliable tool for uncertainty quantification.
Bagging (Bootstrap Aggregation)
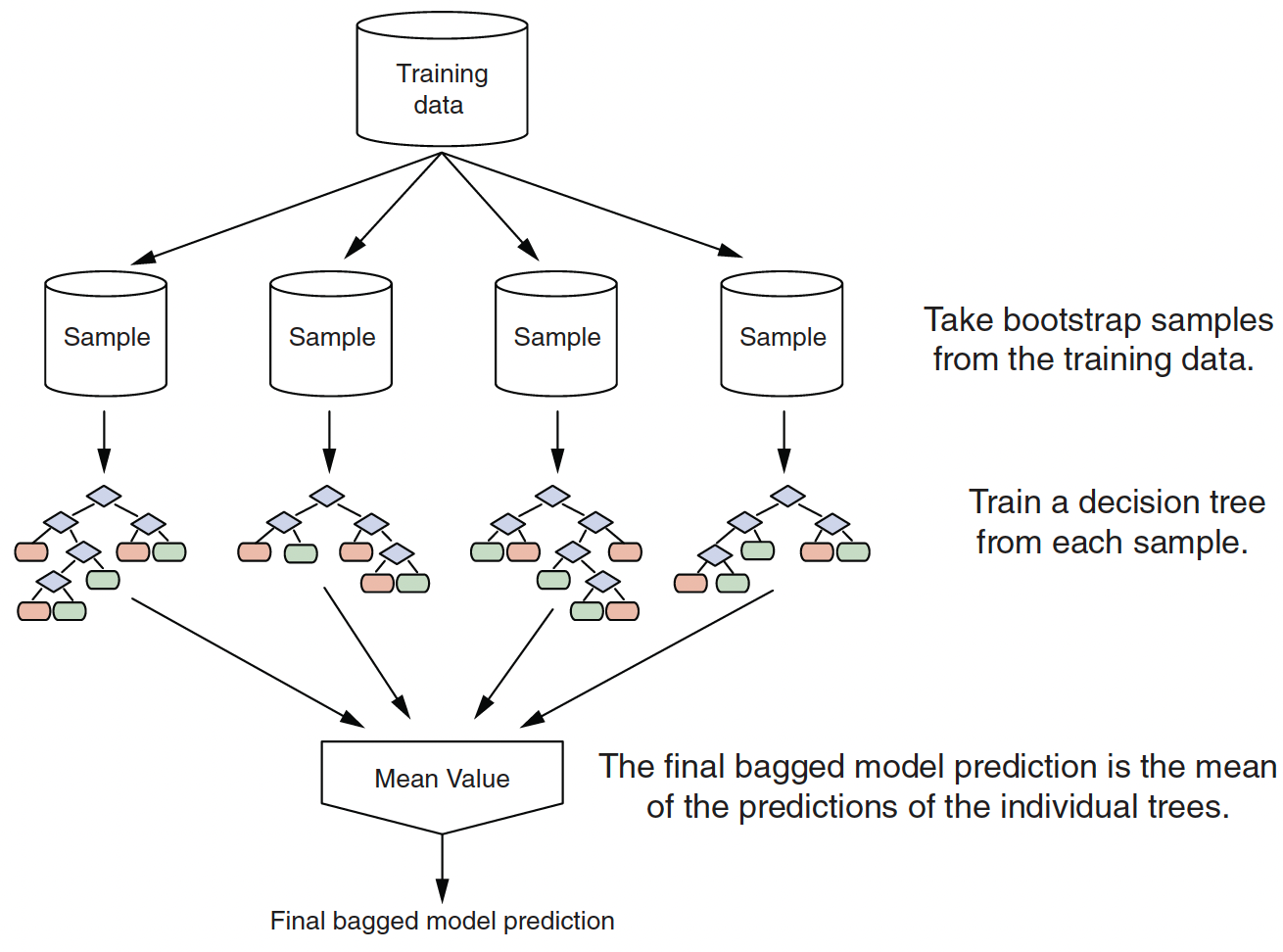
- Real structure that persists across datasets shows up in the average.
- A bagged ensemble of trees is also less likely to overfit the data.
Random Forest Diagram
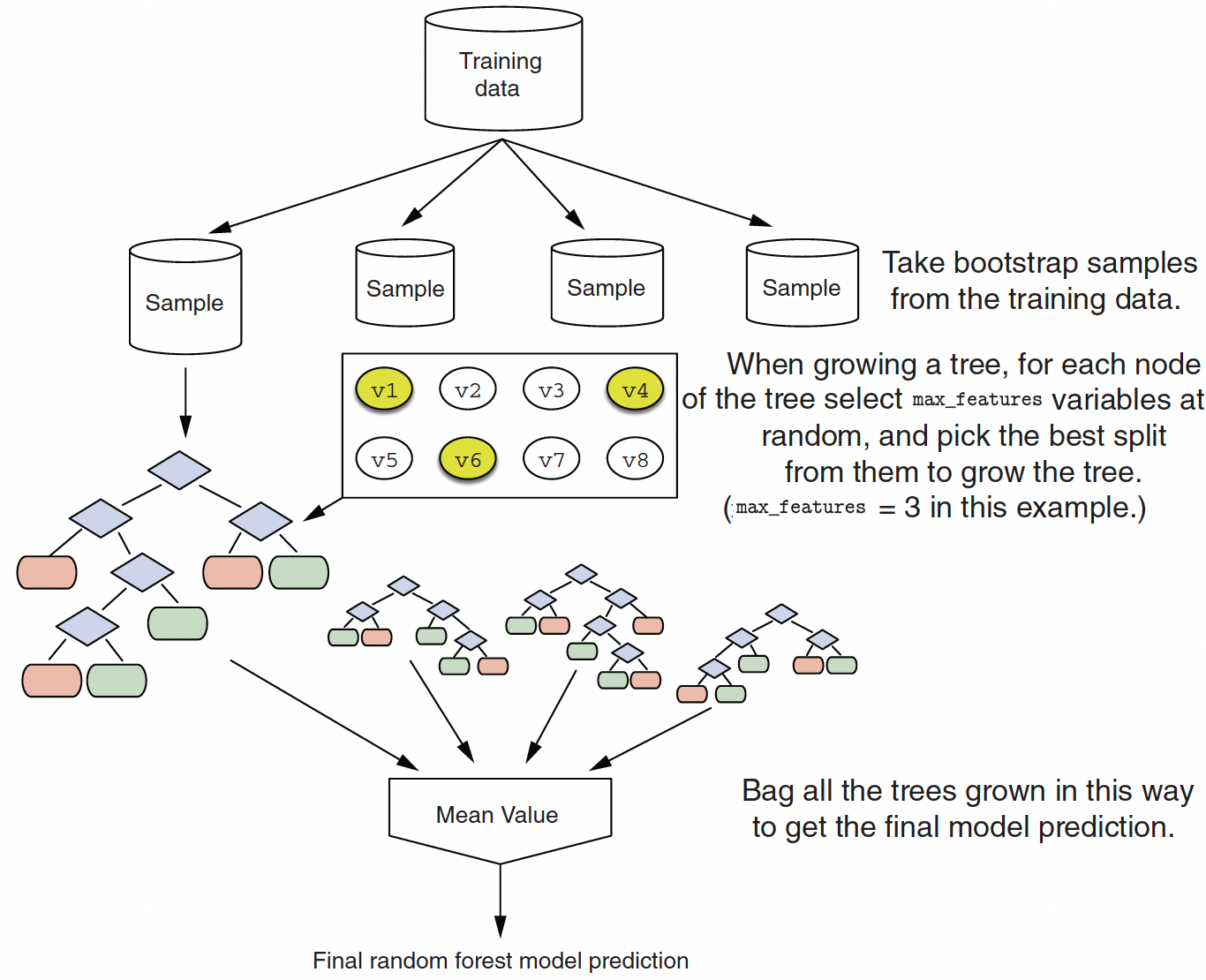
- The final ensemble of trees is bagged to make the random forest predictions.
Out-of-bag Samples for Estimating the Accuracy
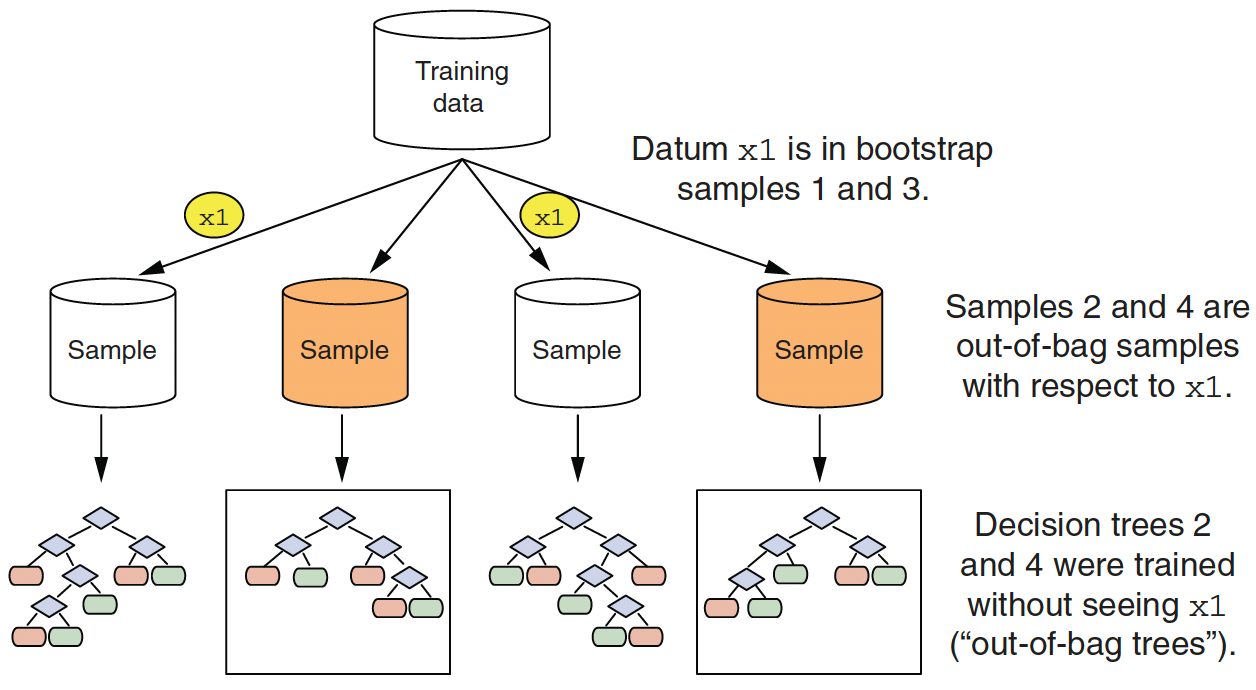
Out-of-bag samples for observation x1
- Since random forest uses a large number of bootstrap samples, each data point has a corresponding set of out-of-bag samples.
Examining Variable Importance
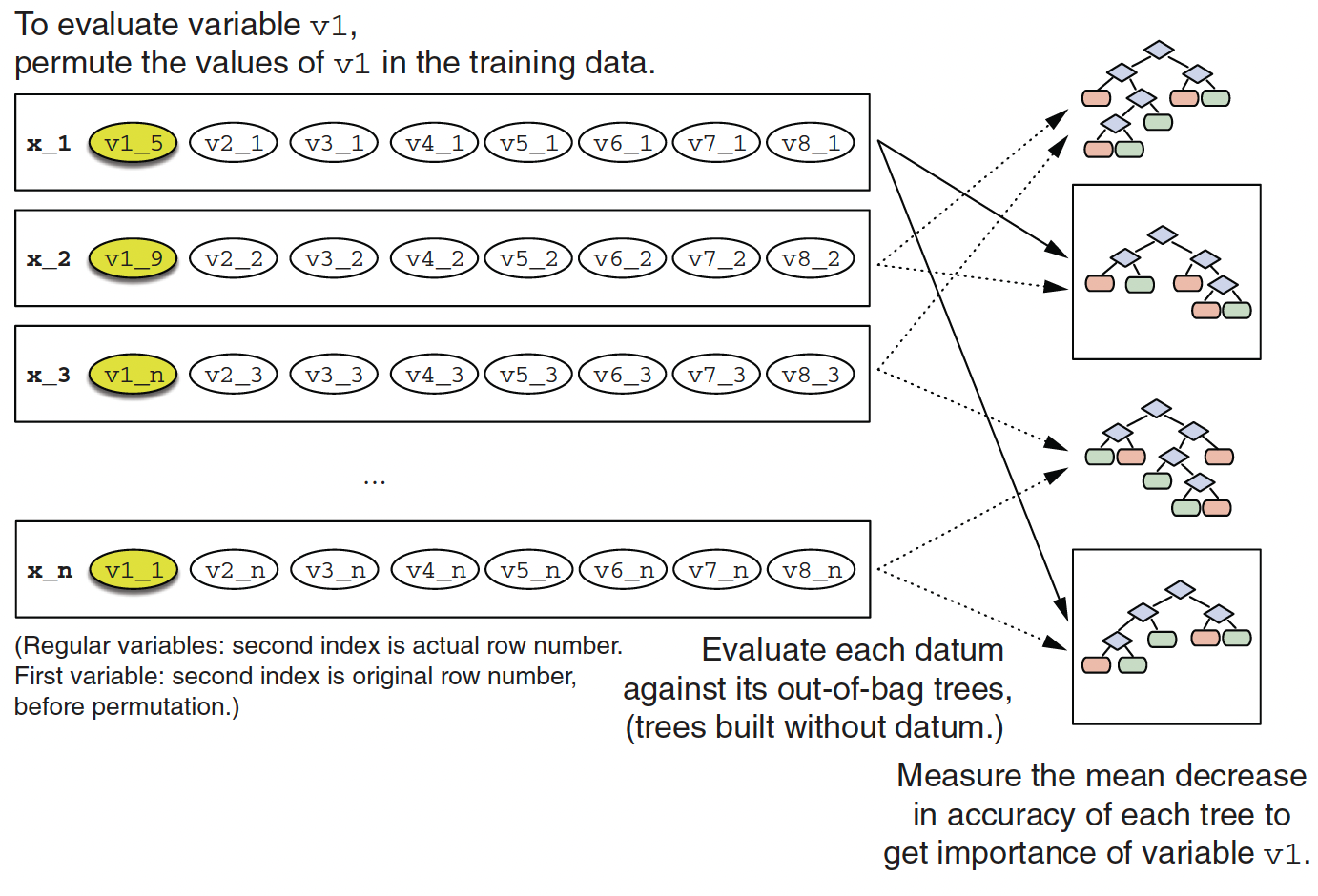
Calculating variable importance of variable v1
Building Up a Gradient-Boosted Tree Model
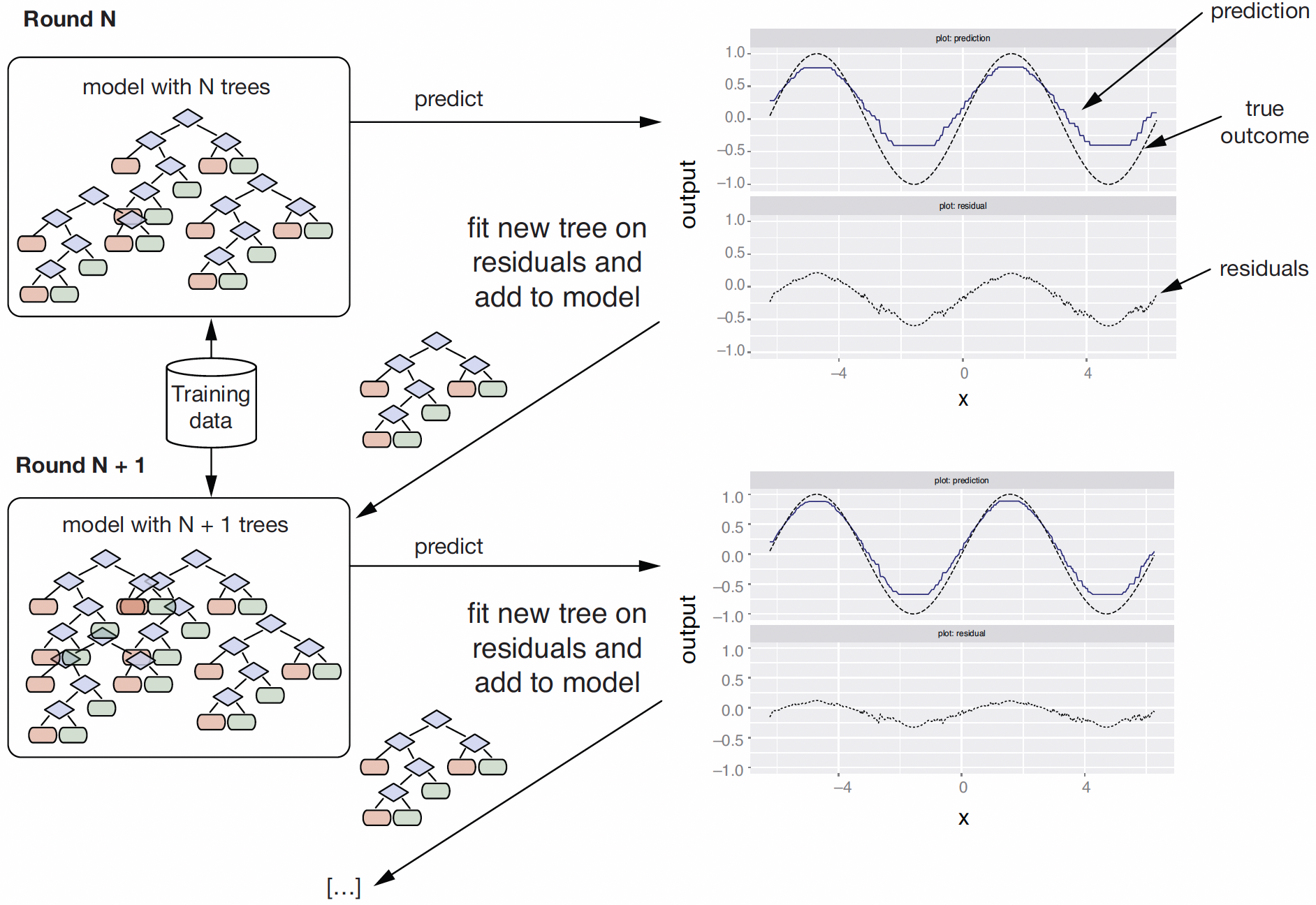
Building up a gradient-boosted tree model
Visual Example of Boosting in Action
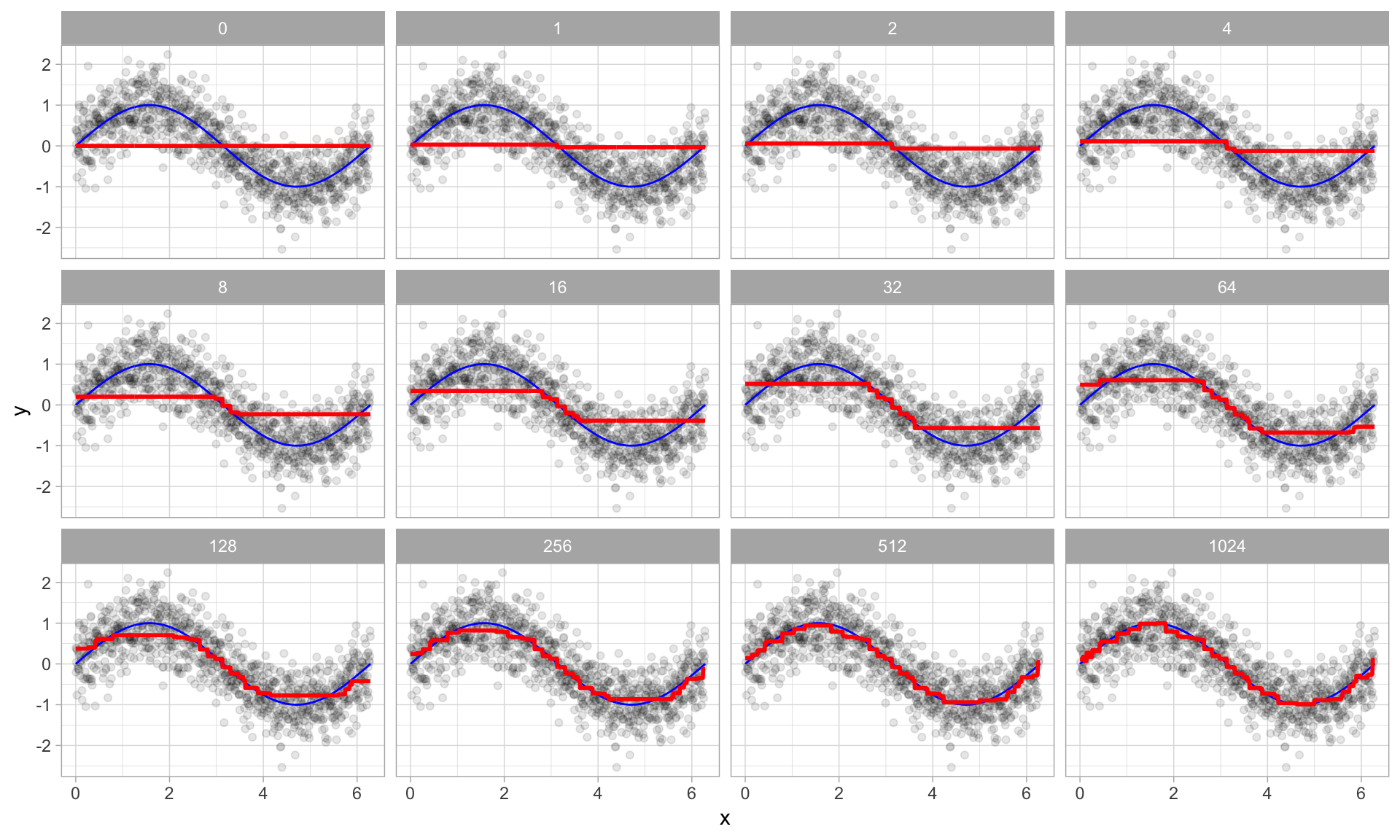
Boosted regression trees as 0-1024 successive trees are added.
Gradient-Boosted Trees
Update the model parameters in the direction of the loss function (e.g., MSE, deviance)’s descending gradient
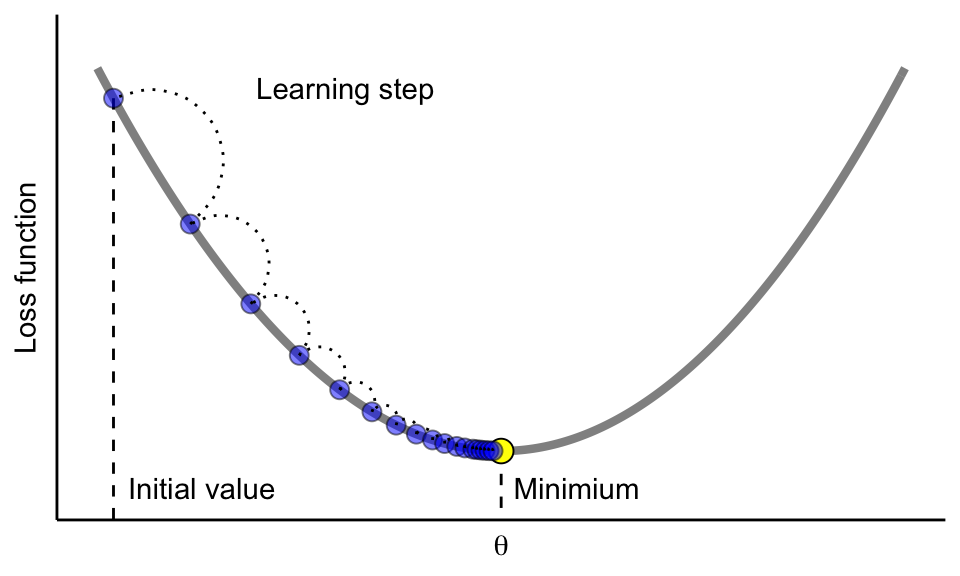
Tune the Learning Rate in Gradient Descent
We need to control how much we update by in each step - the learning rate
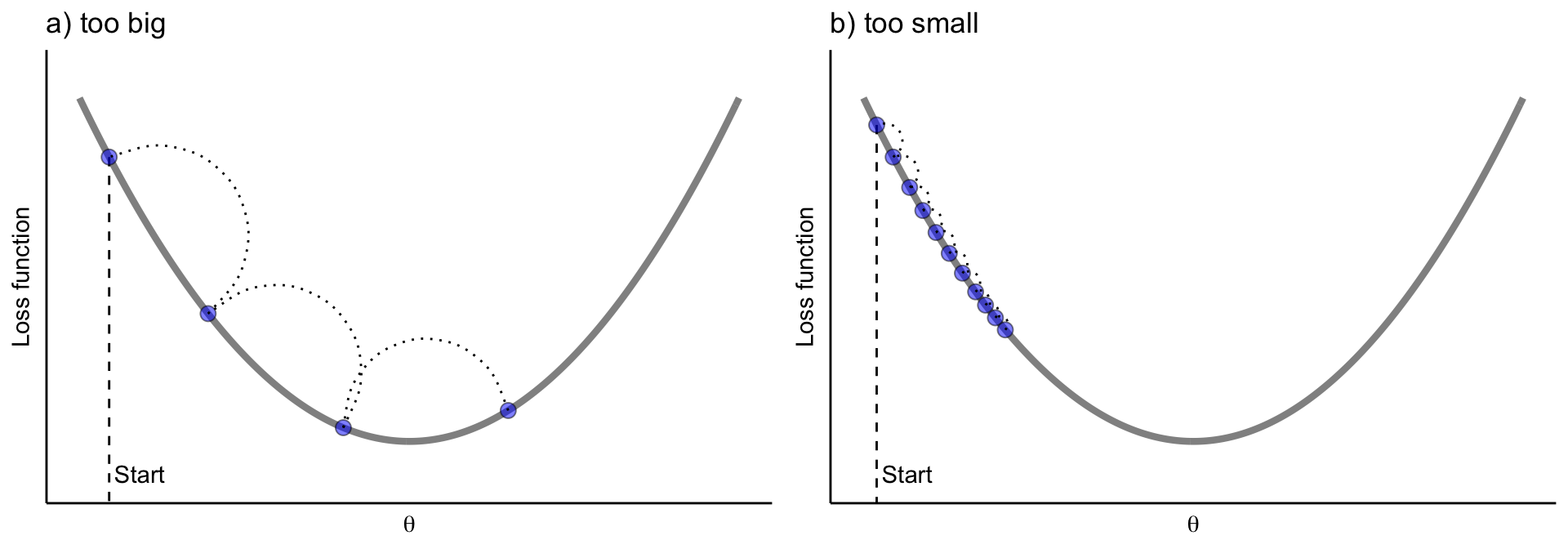
- Too large: overshoots the minimum — the model bounces back and forth and may never converge.
- Too small: takes tiny steps — eventually finds the minimum but requires far more trees and is slow.
- A good learning rate (
eta) takes moderate, steady steps downhill to the minimum loss.
eXtreme Gradient Boosting with XGBoost

XGBoostis one of the most popular open-source library for the gradient boosting algorithm.