Lecture 5
Tree-based Model I: Decision Trees
March 23, 2026
Decision Tree Terminologies
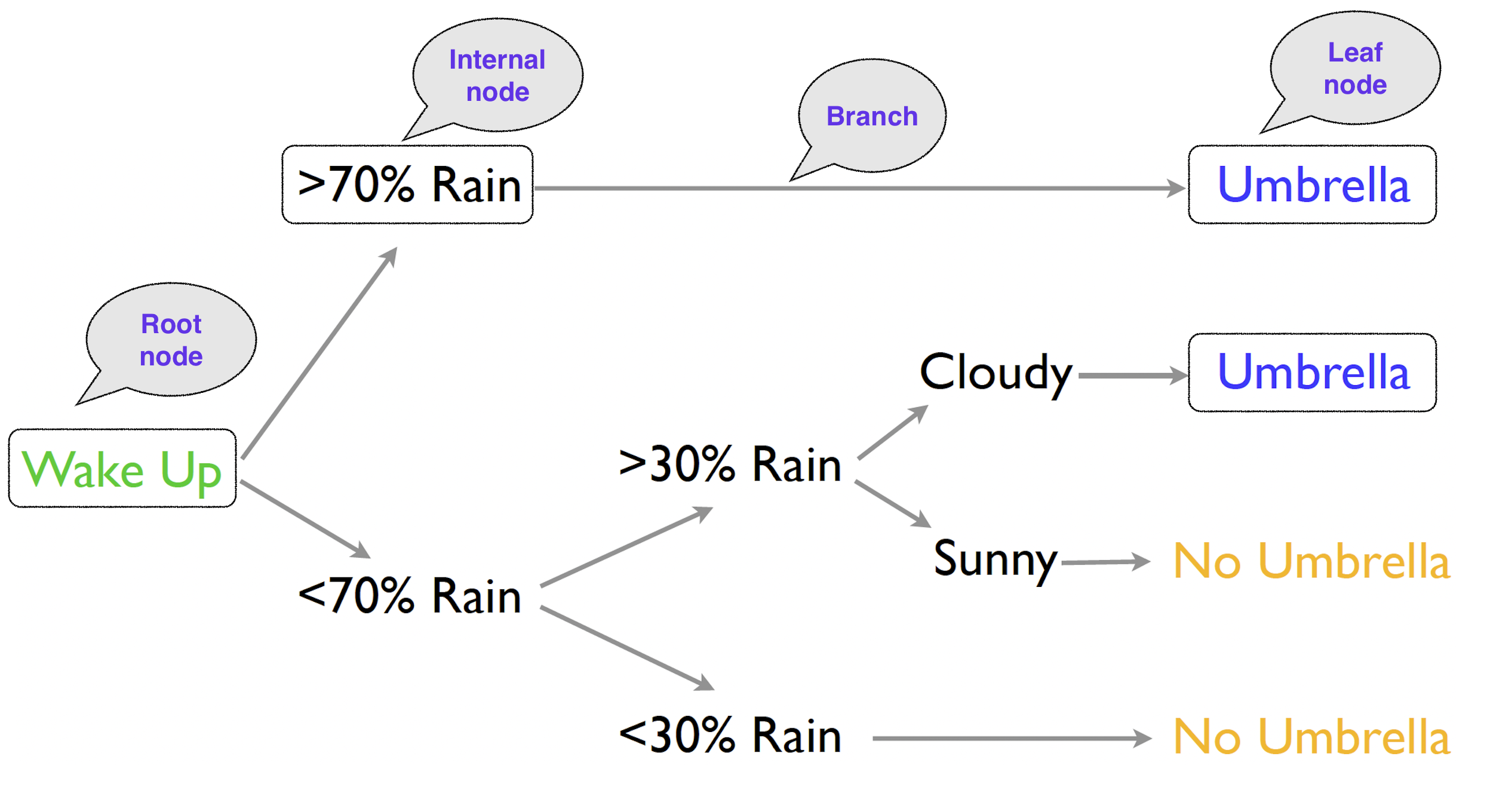
- Each decision is a node, and the final prediction is a leaf node.
Tree-logic
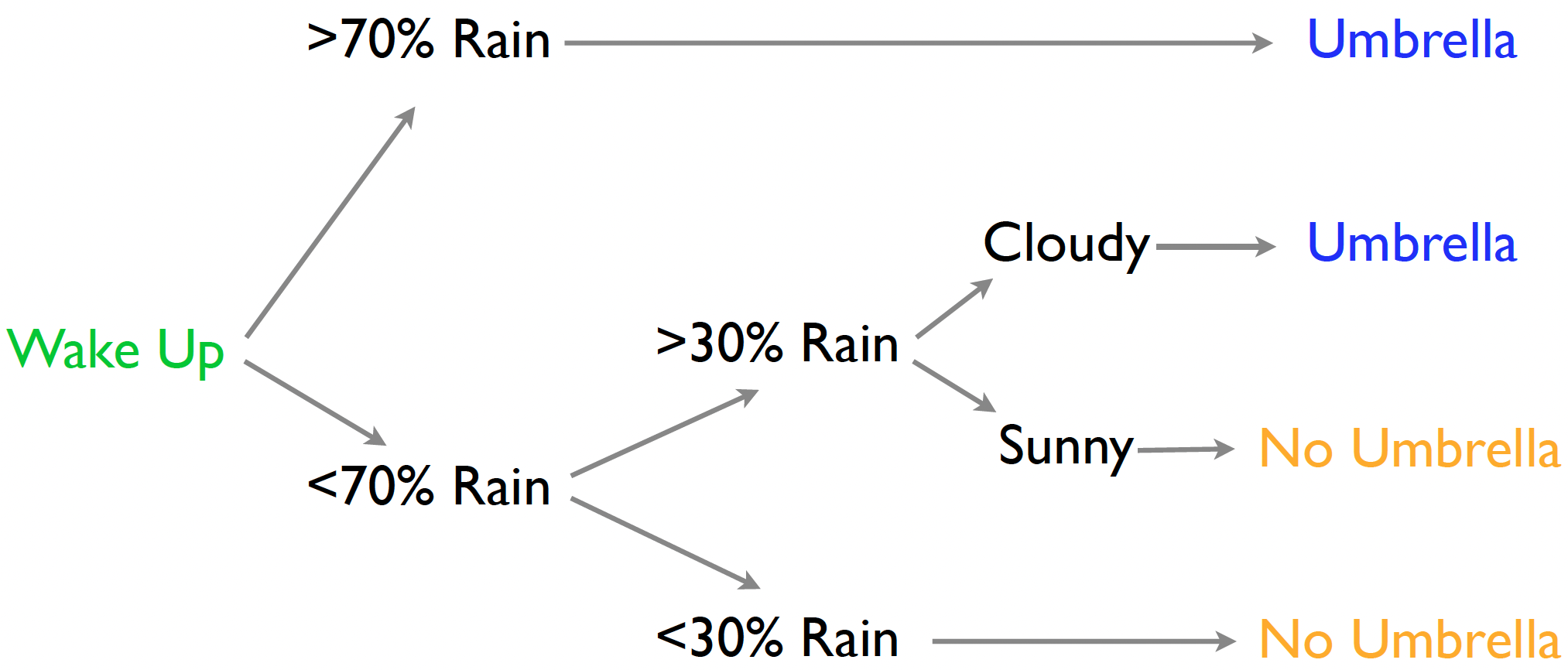
- Tree-logic uses a series of steps to come to a conclusion.
- The trick is to have mini-decisions combine for good choices.
- We make a prediction for an observation by following its path along the tree.
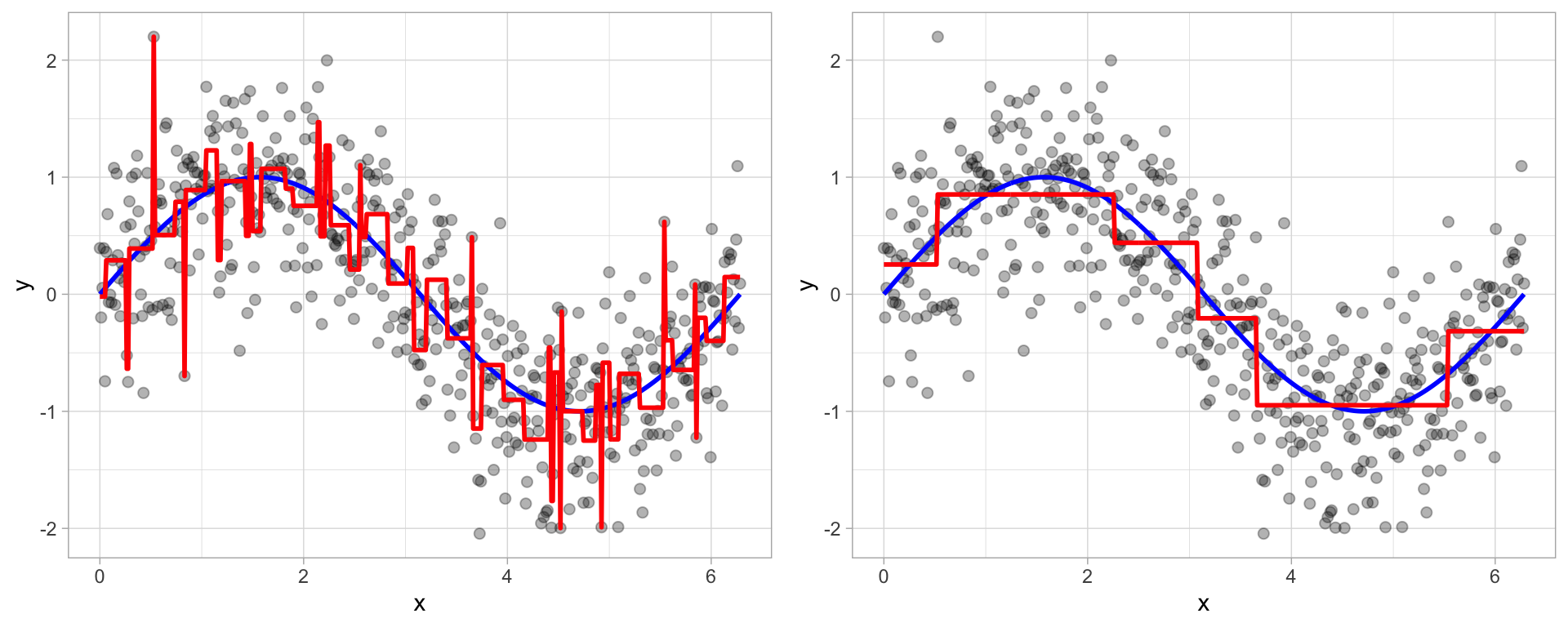
Regression Tree with NBC Shows
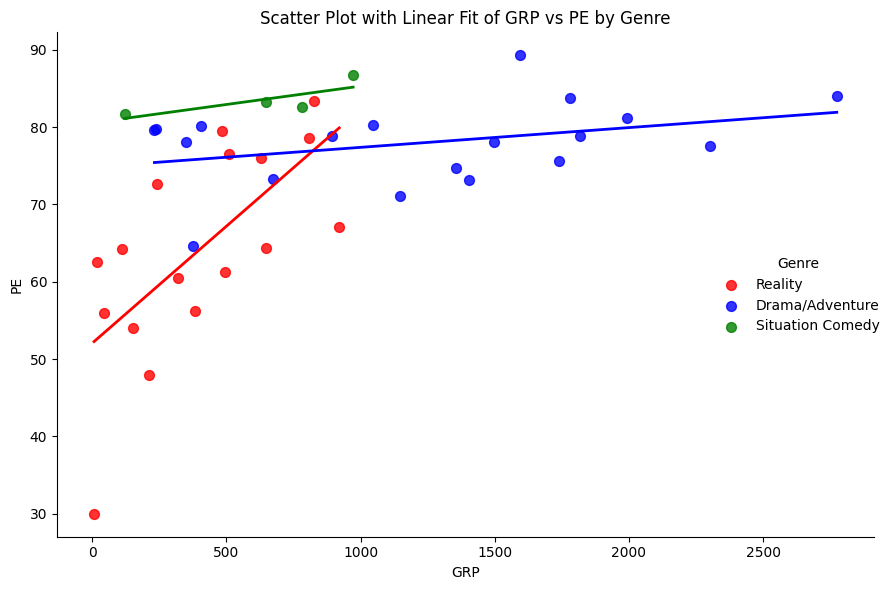
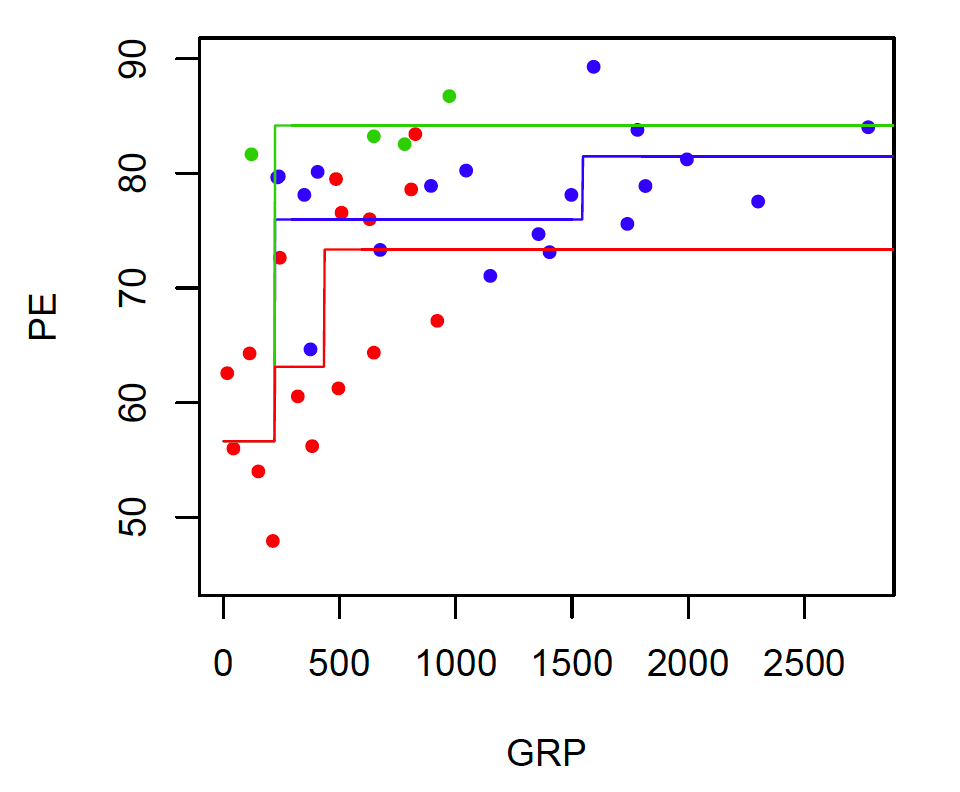
- Nonlinear: PE increases with GRP, but in jumps
- Trees automatically learn non-linear response functions and will discover interactions between predictors.
- This flexibility is helpful, but it also raises the risk of overfitting.
Tune the maximum tree depth or minimum node size
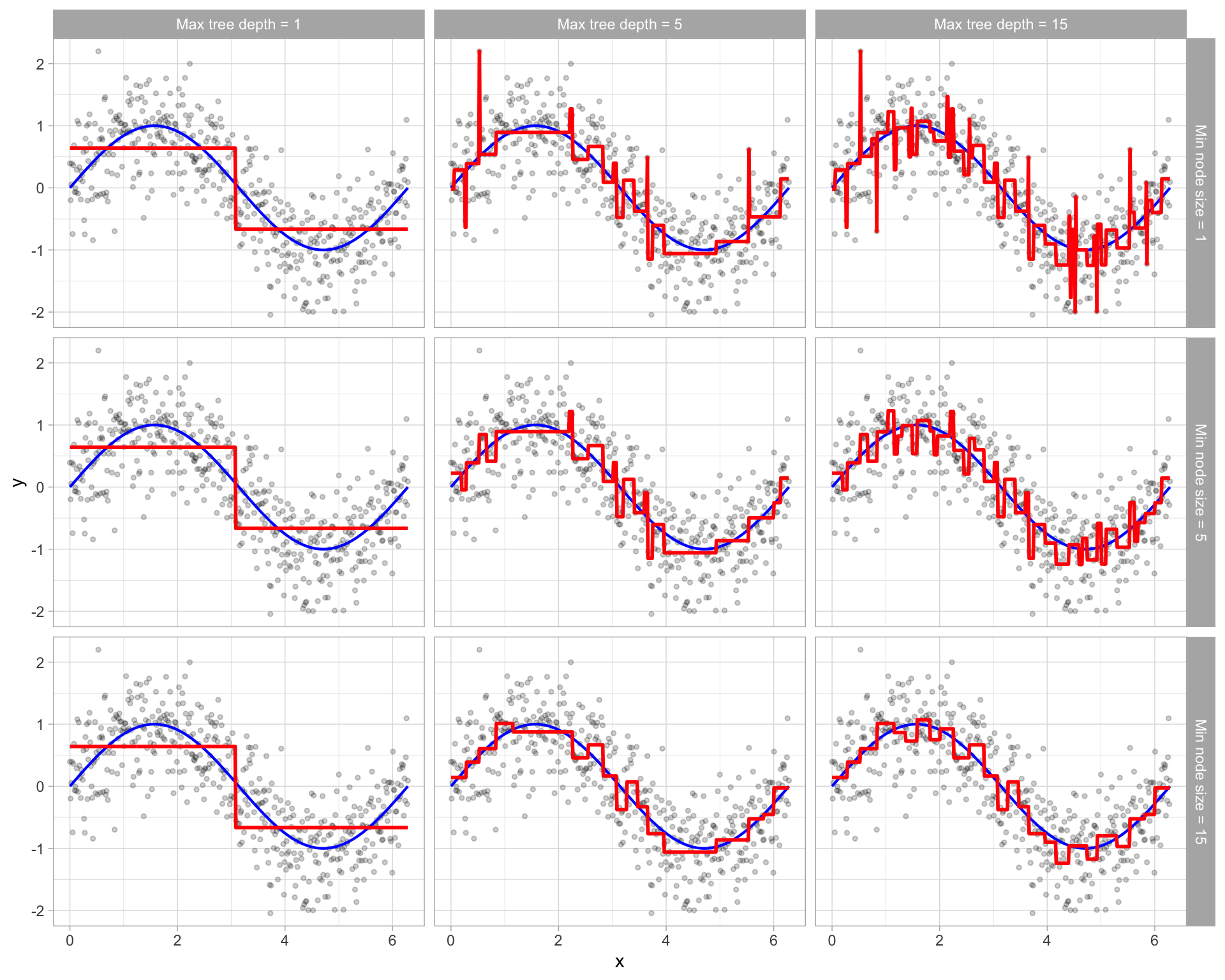
Prune the tree by tuning cost complexity
We can grow a very large complicated tree, and then prune back to an optimal subtree using a cost complexity parameter \(\alpha\) (like \(\lambda\) for regularization)
\(\alpha\) penalizes objective as a function of the number of terminal nodes
e.g., we want to minimize \(SSE + \alpha \cdot (\# \text{ of terminal nodes})\)