Lecture 5
Distributed Computing Framework; Apache Hadoop and Spark; PySpark
February 5, 2025
Distributed Computing Framework (DCF)

- Massive Jigsaw Puzzle:
- Solving alone takes forever.
- Invite friends to work on different sections simultaneously.
- DCF Role:
- Acts like a team manager.
- Splits large problems into manageable tasks.
- Coordinates parallel work across multiple computers (nodes).
Hadoop
Introduction to Hadoop

- Definition
- An open-source software framework for storing and processing large data sets.
- Components
- Hadoop Distributed File System (HDFS): Distributed data storage.
- MapReduce: Data processing model.
Hadoop
Introduction to Hadoop
- Purpose
- Enables distributed processing of large data sets across clusters of computers.
Hadoop
Hadoop Architecture - HDFS
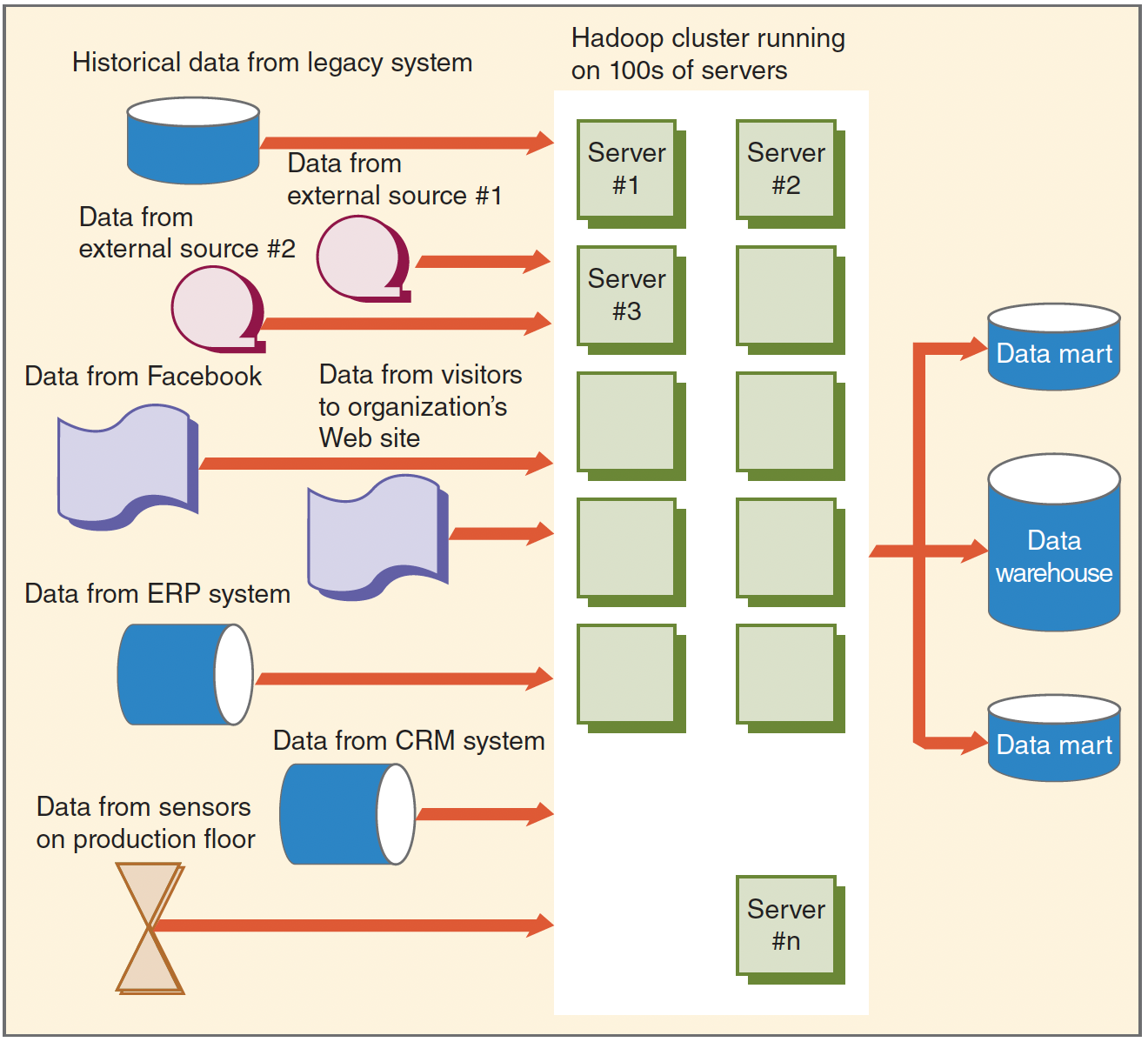
- HDFS
- Divides data into blocks and distributes them across different servers for processing.
- Provides a highly redundant computing environment
- Allows the application to keep running even if individual servers fail.
Hadoop
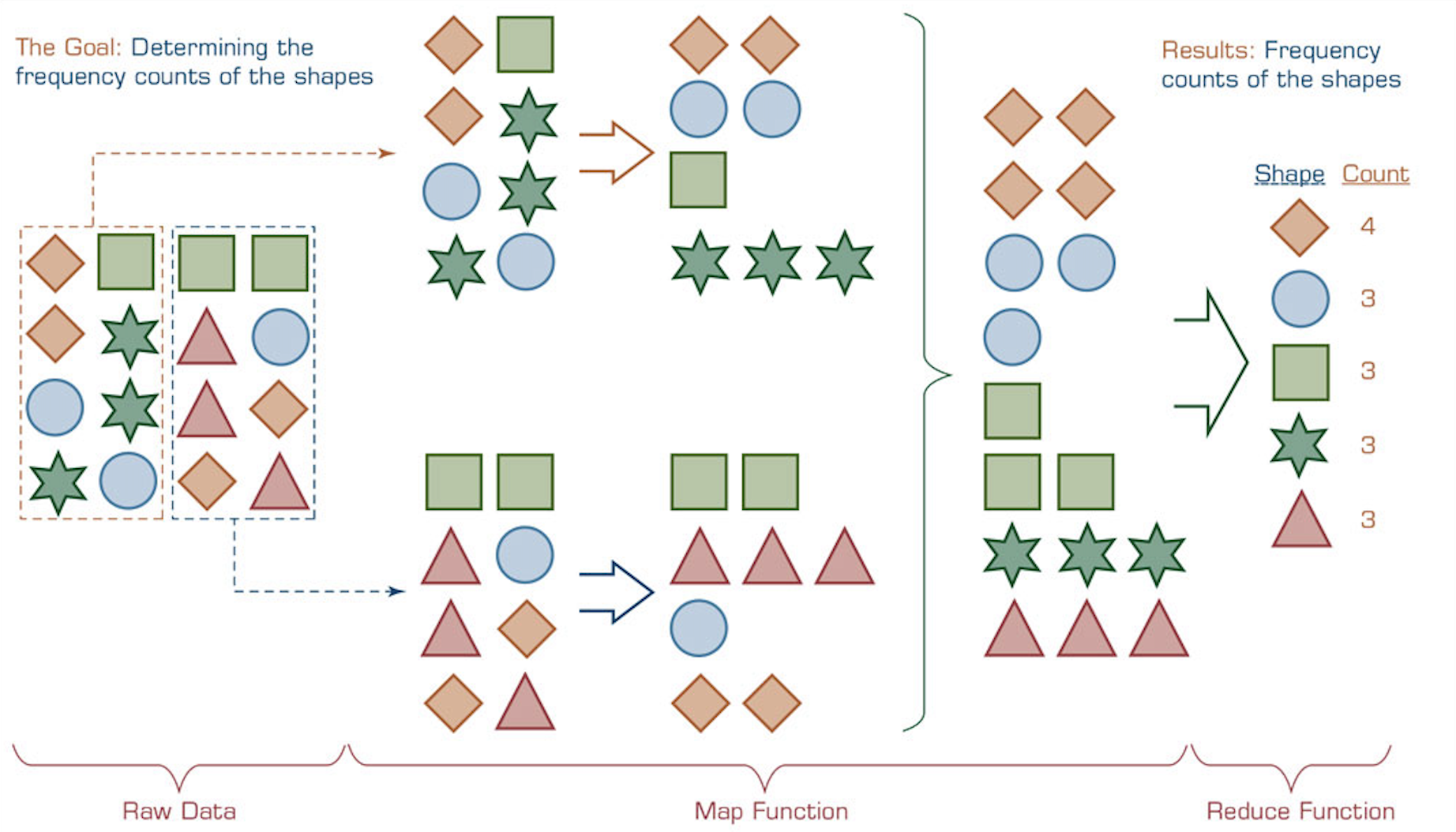
Hadoop Architecture - MapReduce
Spark
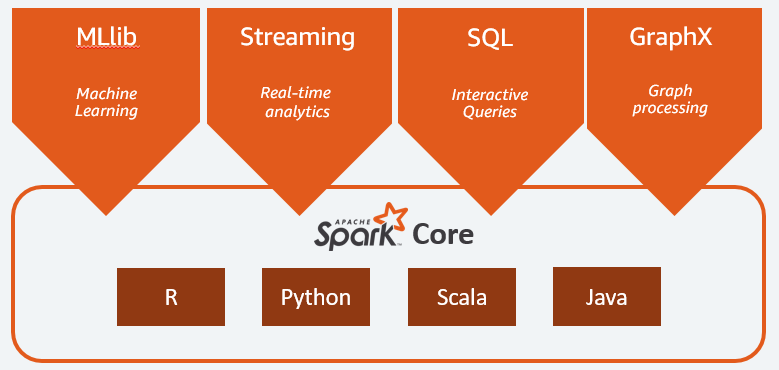
- Apache Spark: distributed processing system used for big data workloads. a unified computing engine and computer clusters
- It contains a set of libraries for parallel processing for data analysis, machine learning, graph analysis, and streaming live data.
Spark Application Structure on a Cluster of Computers
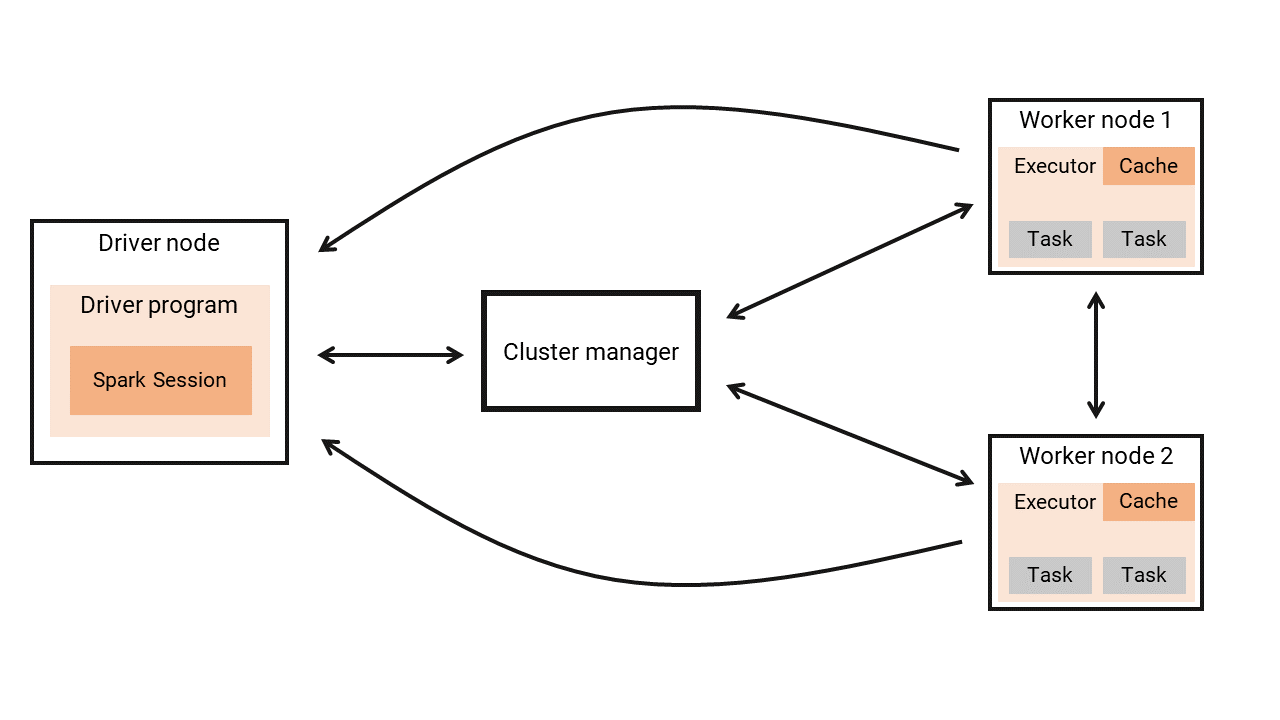
- Driver Process
- Communicates with the cluster manager to acquire worker nodes.
- Breaks the application into smaller tasks if resources are allocated.
Spark Application Structure on a Cluster of Computers
- Cluster Manager
- Decides if Spark can use cluster resources (machines/nodes).
- Allocates necessary nodes to Spark applications.
Spark Application Structure on a Cluster of Computers
- Worker Nodes
- Execute tasks assigned by the driver program.
- Send results back to the driver after execution.
- Can communicate with each other if needed during task execution.
Apache Spark
Medscape: Real-Time Medical News for Healthcare Professionals
- A medical news app for smartphones and tablets designed to keep healthcare professionals informed.
- Provides up-to-date medical news and expert perspectives.
- Real-Time Updates:
- Uses Apache Storm/Spark to process about 500 million tweets per day.
- Automatic Twitter feed integration helps users track important medical trends shared by physicians and medical commentators.
RDD and PySpark DataFrame
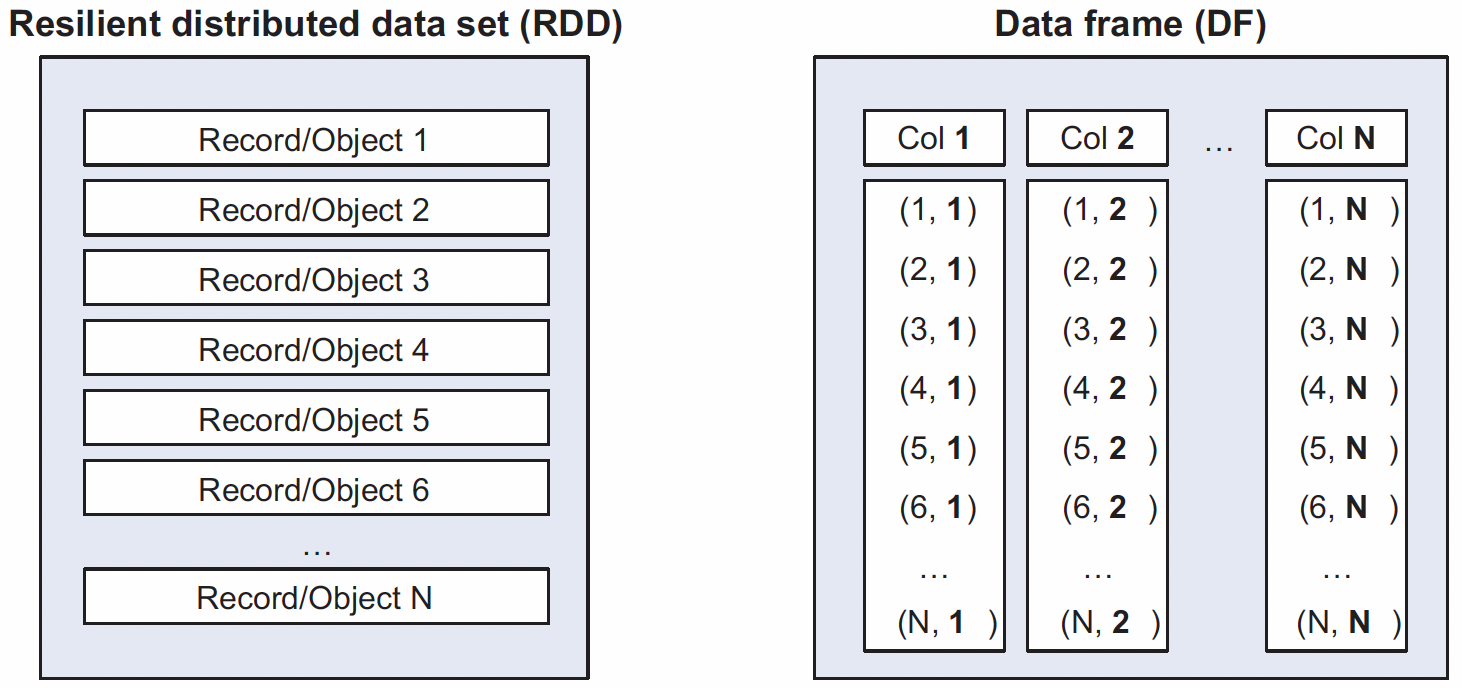
- In the RDD, we think of each row as an independent entity.
- With the
DataFrame, we mostly interact with columns, performing functions on them.- We still can access the rows of a
DataFramevia RDD if necessary.
- We still can access the rows of a