Lecture 4
K-fold Cross-Validation; Bias-Variance Trade-off; Regularized Regression
February 25, 2026
K-fold Cross-Validation
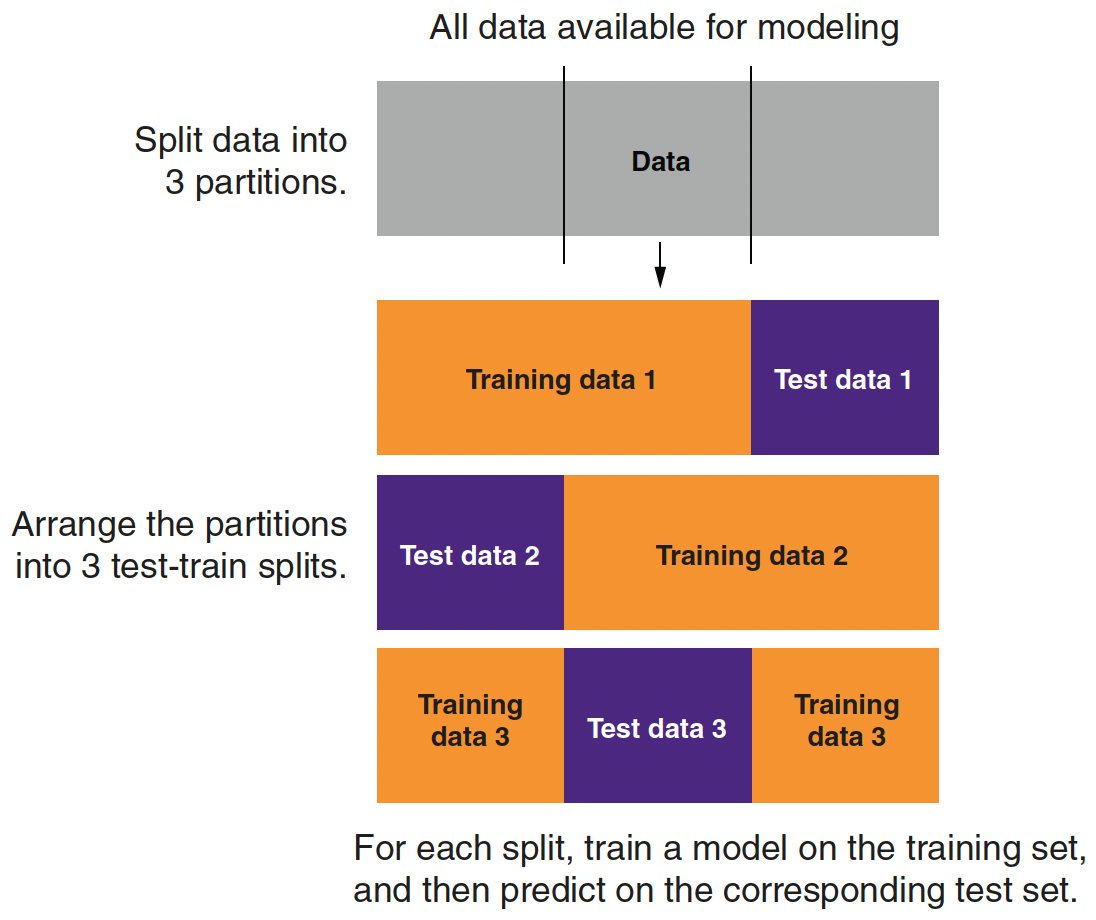 Partitioning Data for 3-fold Cross-Validation
Partitioning Data for 3-fold Cross-Validation
- A single train–test split uses each subset only once—either for training or for evaluation.
- K‑fold cross-validation divides the training data into K equal parts (folds).
- For each fold \(k=1, \dots, K\):
- Step 1: Train the model on \(K‑1\) folds.
- Step 2: Evaluate the model on the held‑out fold.
- For each fold \(k=1, \dots, K\):
- The average error across folds provides a robust estimate of model performance.
Underfit vs. Optimal vs. Overfit

- Underfit: too simple, so it misses the main structure (systematic pattern) in the data.
- Optimal: complex enough to capture the overall trend, but not so flexible that it chases noise.
- Overfit: fits the training points extremely well, but the curve is too sensitive to small changes, so the shape is not stable and generalizes poorly.
Bias vs. Variance
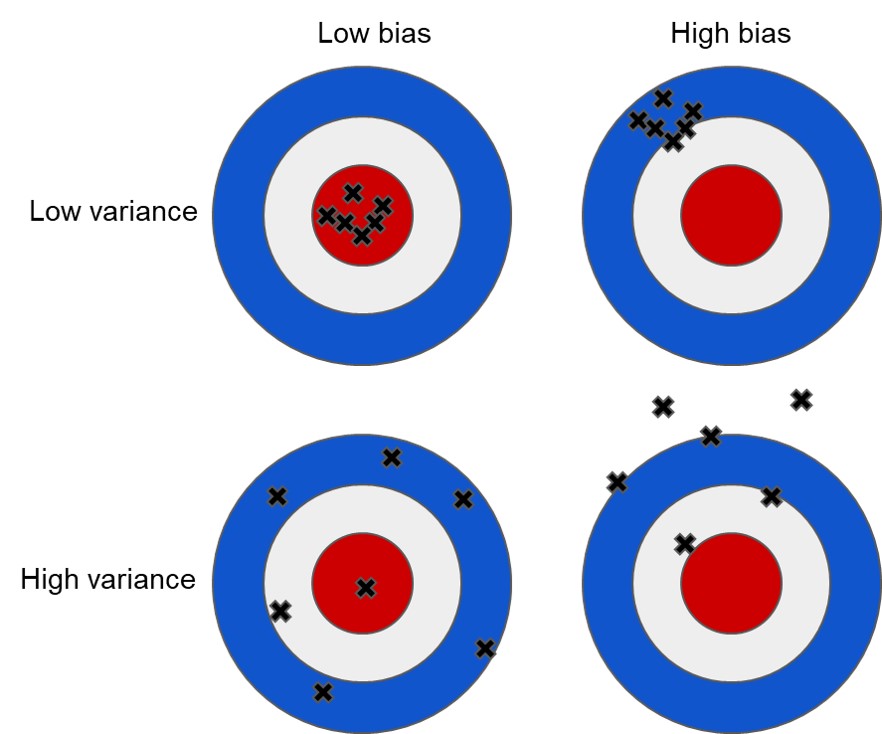
- Think of each black × as the model’s prediction from a different training sample.
- Low bias + low variance (top-left): accurate and stable → best generalization.
- High bias + low variance (top-right): stable but consistently wrong → underfitting.
- Low bias + high variance (bottom-left): right on average but noisy → overfitting risk.
- High bias + high variance (bottom-right): wrong and unstable → usually the worst case.
The Bias–Variance Trade-off Curve
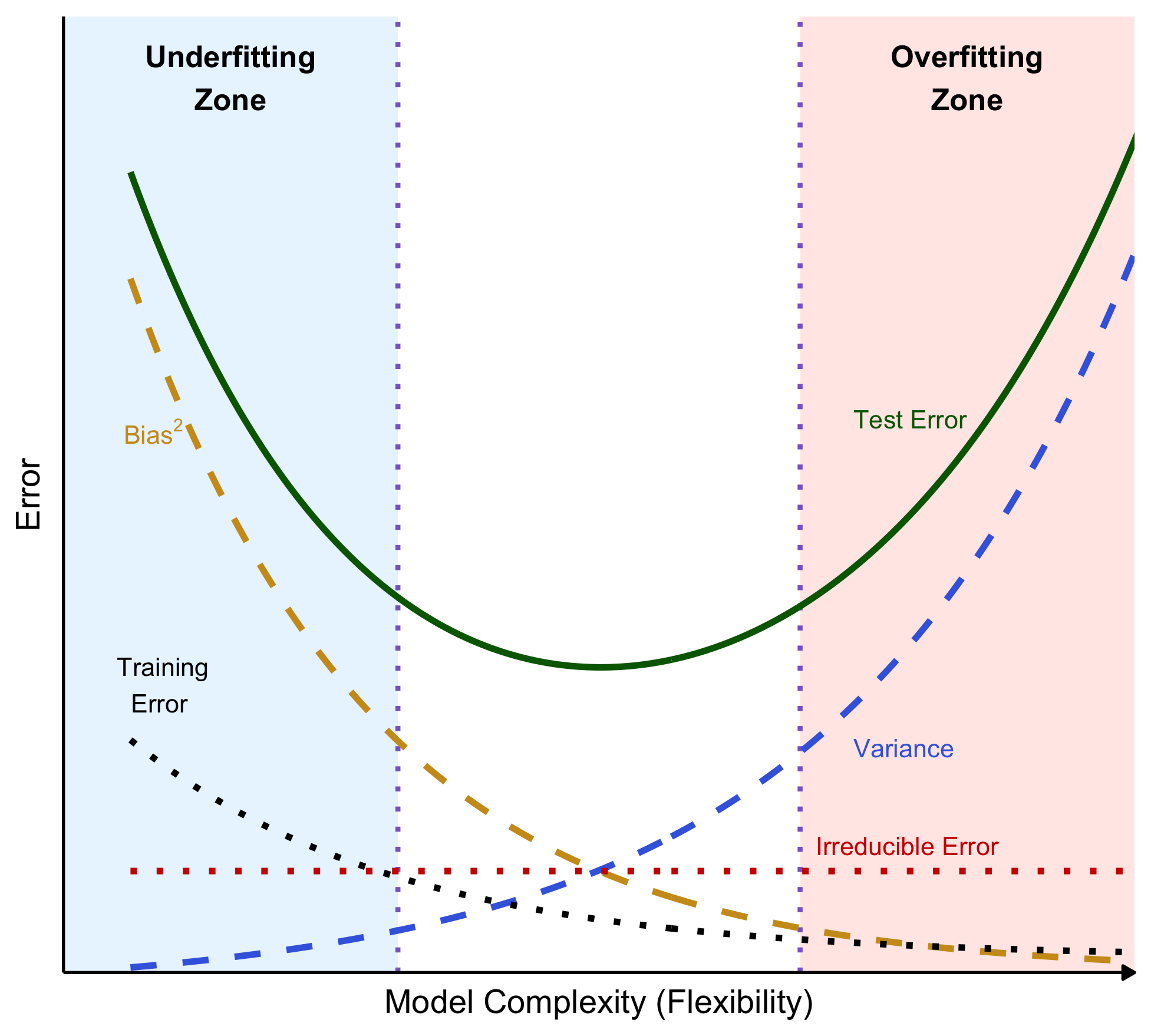
- Bias\(^2\): simple models cannot represent complex patterns → high systematic error
- Adding flexibility lets the model capture real structure → lower bias
- Variance: flexible models adapt strongly to the specific training sample you happened to observe
- if you re-sample the training data, the fitted model can change a lot
- The “best” complexity is near the bottom of the U (minimum test error).
How Expensive Is It To Make \(\beta\) Large?
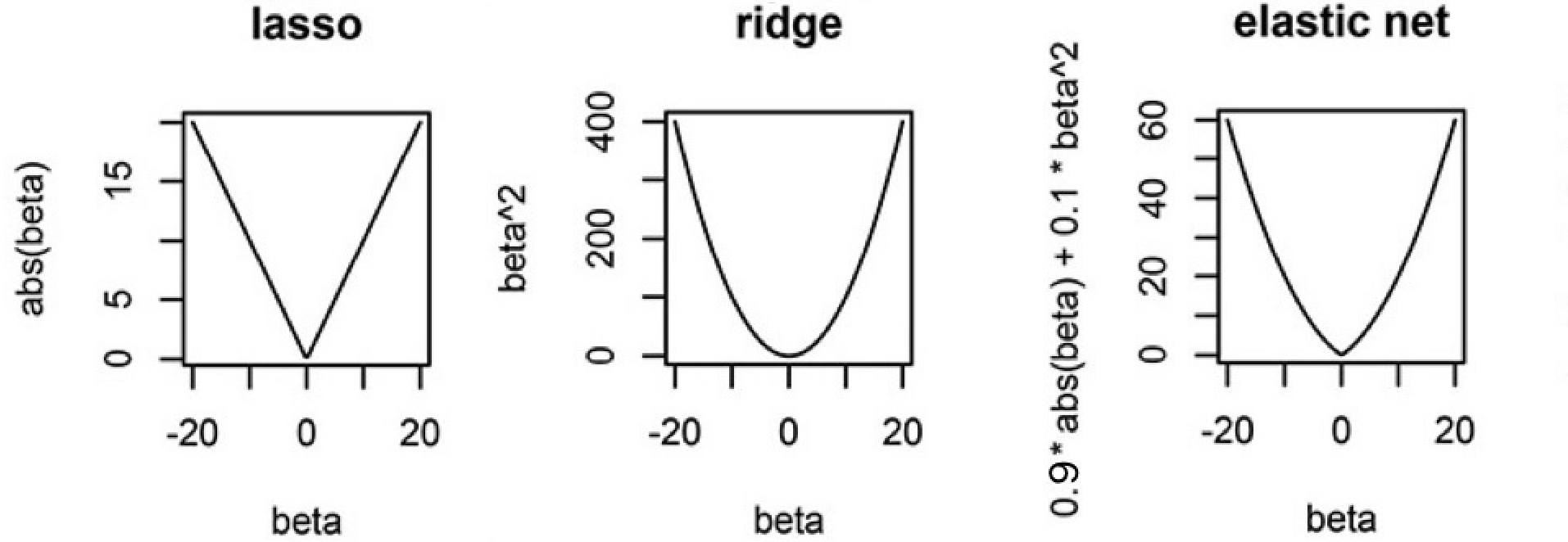
- Lasso (L1) Penalty (\(|\beta|\)):
- Each unit increase in \(\beta\) adds a constant penalty, regardless of \(\beta\) ’s size.
- Drives some coefficients exactly to zero, acting as a predictor selection mechanism.
- Ridge (L2) Penalty (\(\beta^2\)):
- Gently penalizes small-to-moderate deviations from zero, but penalty increases quickly for large \(\beta\).
- Shrinks coefficients but does not set them exactly to zero.
Intuition on Different Penalties
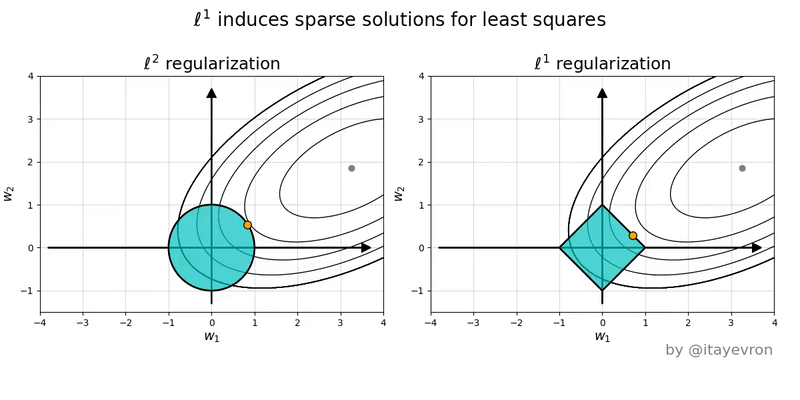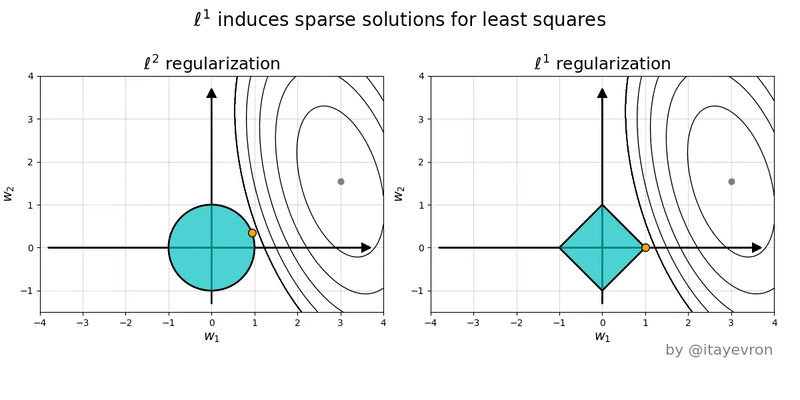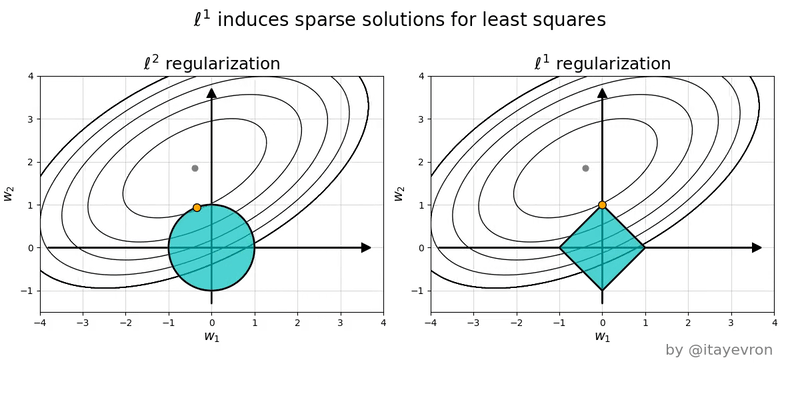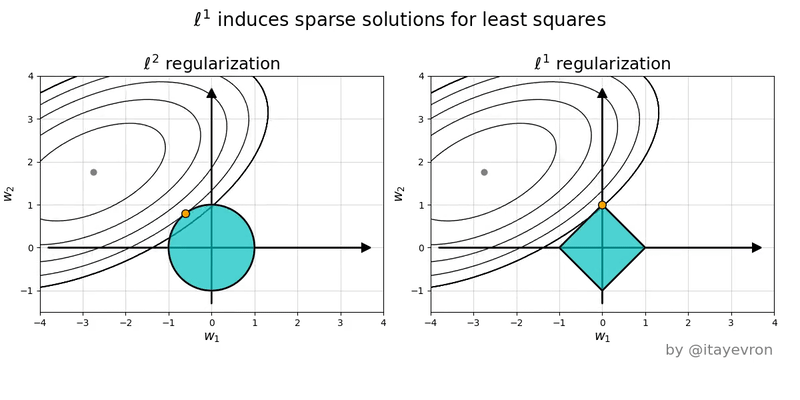
- The ellipses are contours of equal SSE (same fit quality).
- The shape is the constraint/penalty region.
- Lasso induces corner solutions!
- Lasso has corners, and corners create zeros.
Sparse Matrix
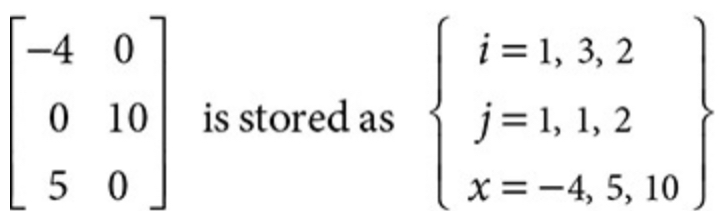
R’s \(\texttt{glmnet}\) package uses a sparse matrix
A sparse matrix is a matrix with many zero entries
A sparse matrix is almost essential in big data analysis because of its lower storage costs and faster computation.
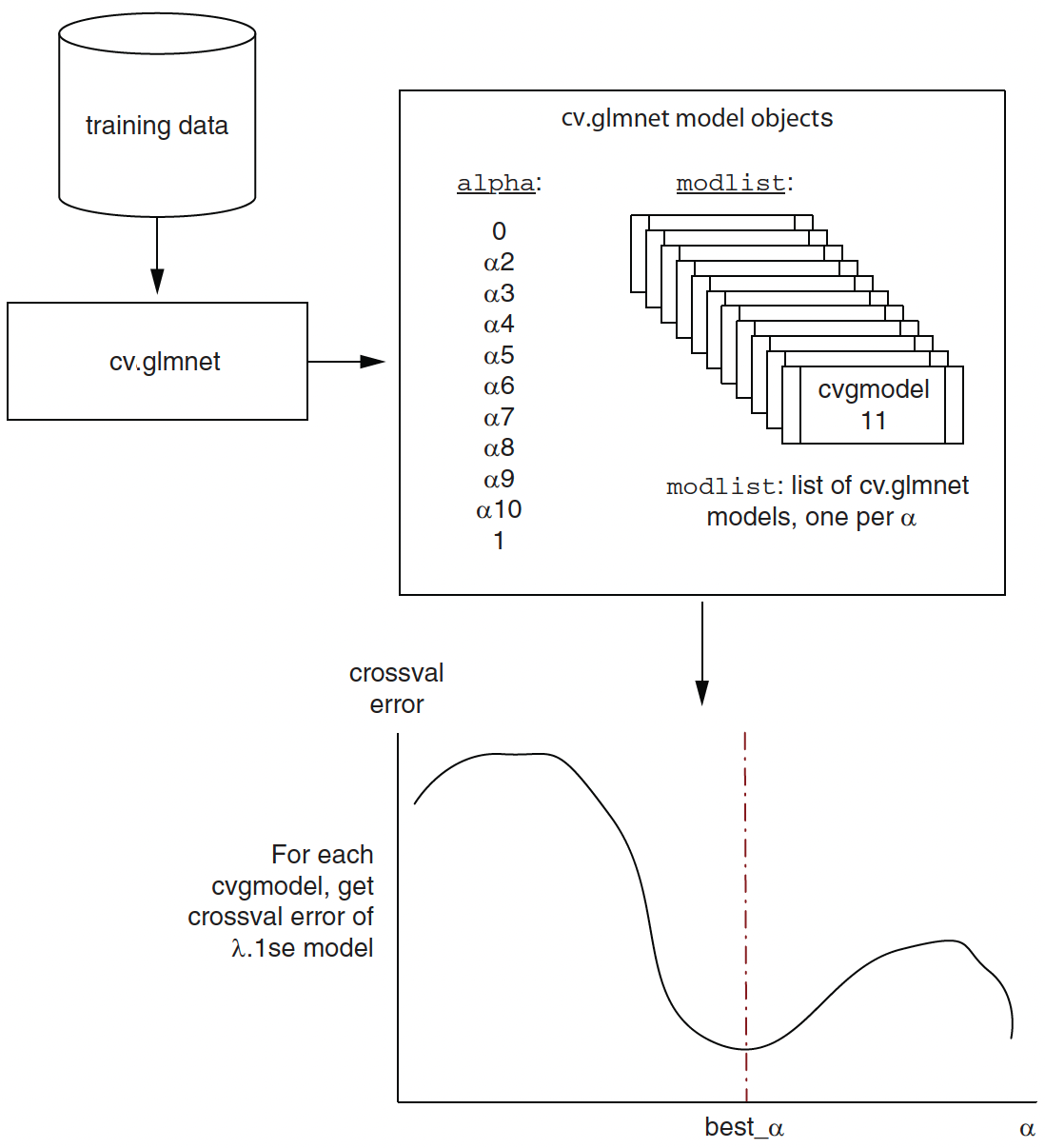
Lasso/Ridge Regression with Cross-Validation in R
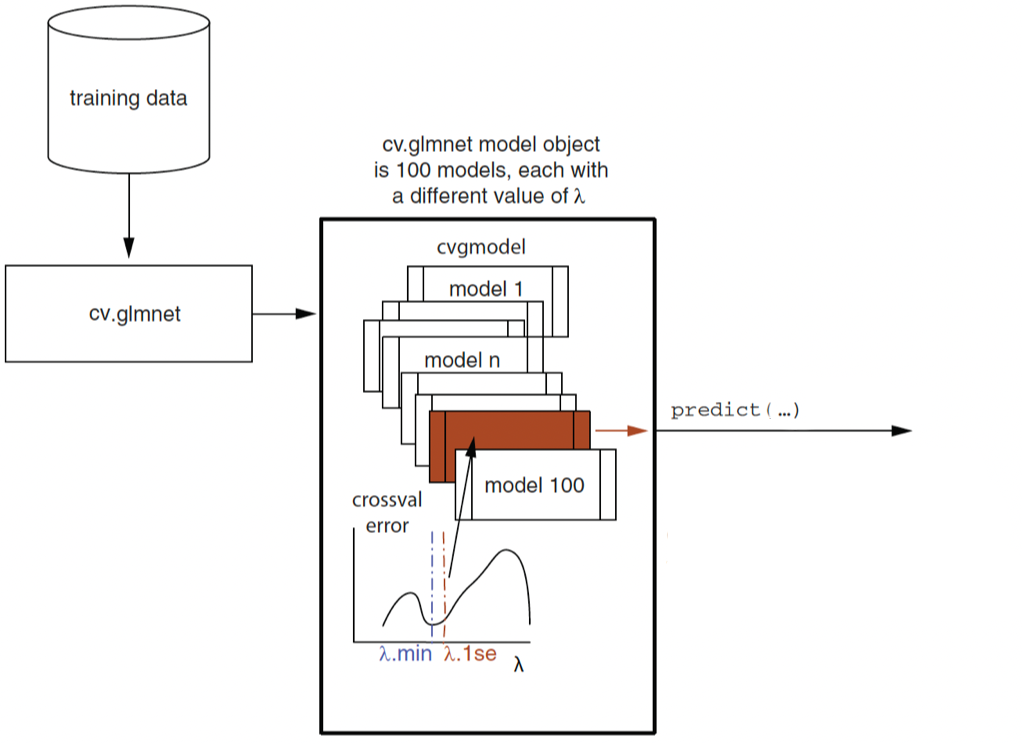
- \(\lambda_{min}\): the \(\lambda\) for the model with the minimum cross-validation (CV) error
- \(\lambda\texttt{.1se}\): corresponds to the model with cross-validation error, which is \(\textit{one standard error (se)}\) of CV error above the minimum CV error.
Elastic Net Regression with Cross-Validation in R