Lecture 17
Data Collection with APIs
April 11, 2025
Spyder IDE
Keyboard Shortcuts
- To set your keyboard shortcuts,
- Preferences > Keyboard Shortcuts > Search “run” and/or “comment”
- Set the shortcuts for (1) run selection; (2) run cell; (3) toggle comment; (4) blockcomment; and (5) unblockcomment
- Default shortcuts
- Run selection (a current line): F9
- Run cell: Ctrl + Enter
# %%defines a coding cell
- Comment (
#): Ctrl/command + 1 - Block-comment: Ctrl/command + 4
- Unblock-comment: Ctrl/command + 5
Web-scrapping Tips
Mac
Use a full screen mode for your Spyder IDE.
Use a trackpad gesture with three fingers to move across screens, or command+tab to move between a Chrome web browser and a Spyder IDE.
Windows
- Use Alt + Tab to move between a Chrome web browser and a Spyder IDE.
Web Scraping Tips
On Mac
- Use full-screen mode in your Spyder IDE for a distraction‑free environment.
- Use a three‑finger swipe on your trackpad or press Command+Tab to quickly switch between Chrome and Spyder IDE.
On Windows
- Press Alt+Tab to efficiently switch between your Chrome browser and Spyder.
APIs
Clients and servers
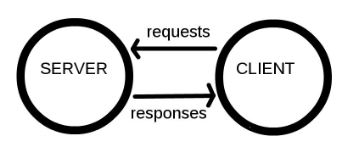
- Computers connected to the web are called clients and servers.
Clients are the typical web user’s internet-connected devices (e.g., a computer connected to Wi-Fi) and web-accessing software available on those devices (e.g., Firefox, Chrome).
Servers are computers that store webpages, sites, or apps.
When a client device wants to access a webpage, a copy of the webpage is downloaded from the server onto the client machine to be displayed in the user’s web browser.
Hypertext Transfer Protocol Secure (HTTPS)
Hypertext Transfer Protocol (HTTP) is a language for clients and servers to speak to each other.
Hypertext Transfer Protocol Secure (HTTPS) is an encrypted version of HTTP that provides secure communication between them.
When we type a web address with “https://” into our browser:
- The browser finds the address of the server that hosts the website.
- The browser and server establish a secure connection.
- The browser sends an HTTPS request to the server, asking for the website’s content.
- If the server approves the request, it responds with a 200 OK message and sends the encrypted website data to the client.
- The browser decrypts and displays the website securely.
HTTP Status Codes
- The
requestslibrary is the de facto standard for making HTTP requests in Python.
- 200 → The request is successful, and the server sends the requested content.
API: Key Concepts
- API stands for Application Programming Interface.
- It enables data transmission between client and server.
- Methods: The “verbs” that clients use to talk with a server.
- The main one that we’ll be using is
GET(i.e., asking a server to retrieve information). Other common methods includePOST,PUT, andDELETE.
- The main one that we’ll be using is
- Requests: What the client asks of the server.
- Response: The server’s response, which includes
- Status Code (e.g., “404” if not found, or “200” if successful);
- Content (i.e. the content that we’re interested in);
- Header (i.e., meta-information about the response).
Understanding the requests Method
- What is
requests?- A Python library used to make HTTP requests to APIs and websites.
- Supports methods like
GET,POST,PUT,DELETE, etc.
- Using
requests.get():- Sends a
GETrequest to retrieve data from a specified URL. - Commonly used when fetching data from APIs.
- Sends a
import requests
url = 'https://www.example.com/.....'
param_dicts = {.....} # Optional, but we often need this
response = requests.get(url, params=param_dicts)url: API endpoint where data is requested.param_dicts: Dictionary of query parameters sent with the request.
API Endpoints
- In the case of web APIs, we can access information directly from the API database if we specify the correct URL(s).
- These URLs are known as API endpoints.
- Navigate your browser to an API endpoint and we’ll just see a load of the following format of texts:
- JSON (JavaScript Object Notation), or
- XML (Extensible Markup Language).
- We can add a JSONView, a browser extension that renders JSON output nicely in Chrome or Firefox.
Inspecting the Response Object
- Key attributes and methods:
response.status_code: Returns HTTP status code (e.g., 200 for success).response.json(): Converts JSON format data into a Python dictionary.response.text: Decoded text version of theresponse.content
- Best practices:
- Always check
status_codebefore processing the response. - Use
response.json()for easier handling of JSON data.
- Always check
Example: NYC Open Data
NYC Open Data (https://opendata.cityofnewyork.us) is free public data published by NYC agencies and other partners.
Many metropolitan cities have the Open Data websites too:
- Let’s get the NYC’s Payroll Data.
- Open the web page https://data.cityofnewyork.us/City-Government/Citywide-Payroll-Data-Fiscal-Year-/k397-673e in your browser.
- Click the “Actions”, and then “API”
- Copy the API endpoint that appears in the popup box.
import requests
import pandas as pd
endpoint = 'https://data.cityofnewyork.us/resource/ic3t-wcy2.json' ## API endpoint
response = requests.get(endpoint)
content = response.json() # to convert JSON response data to a dictionary
df = pd.DataFrame(content)- The
request.get()method sends aGETrequest to the specified URL. response.json()automatically convert JSON data into a dictionary.- JSON objects have the same format as Python dictionaries.
Example: Federal Reserve Economic Data (FRED)
Most API interfaces will only let you access and download data after you have registered an API key with them.
Let’s download economic data from the FRED https://fred.stlouisfed.org using its API.
You need to create an account https://fredaccount.stlouisfed.org/login/ to get an API key for your FRED account.
As with all APIs, a good place to start is the FRED API developer docs https://fred.stlouisfed.org/docs/api/fred/.
We are interested in series/observations https://fred.stlouisfed.org/docs/api/fred/series_observations.html
The parameters that we will use are
api_key,file_type, andseries_id.Replace “YOUR_API_KEY” with your actual API key in the following web address: https://api.stlouisfed.org/fred/series/observations?series_id=GNPCA&api_key=YOUR_API_KEY&file_type=json
- We’re going to go through the
requests,json, andpandaslibraries.requestscomes with a variety of features that allow us to interact more flexibly and securely with web APIs.
import requests # to handle API requests
import json # to parse JSON response data
import pandas as pd
param_dicts = {
'api_key': 'YOUR_FRED_API_KEY', ## Change to your own key
'file_type': 'json',
'series_id': 'GDPC1' ## ID for US real GDP
}
url = "https://api.stlouisfed.org/"
endpoint = "series/observations"
api_endpoint = url + "fred/" + endpoint # sum of strings
response = requests.get(api_endpoint, params = param_dicts)json(): Converts JSON into a Python dictionary object.
- By default, all columns in the DataFrame from
contentarestring-type.- So, we need to convert their types properly.
- The DataFrame may also contains columns we do not need.
Data Collection with APIs
Let’s do Classwork 11!
Using the New York Times API
Using the New York Times API
Sign Up and Sign In
- Sign up at NYTimes Developer Portal
- Verify your NYT Developer account via email you use.
- Sign in.
Register apps
- Select My Apps from the user drop-down at the navigation bar.
- Click + New App to create a new app.
- Enter a name and description for the app in the New App dialog.
- Click Create.
- Click the APIs tab.
- Click the access toggle to enable or disable access to an API product from the app.
Access the API keys
- Select My Apps from th user drop-down.
- Click the app in the list.
- View the API key on the App Details tab.
- Confirm that the status of the API key is Approved.
Collect Data with pynytimes
While NYTimes Developer Portal APIs provides API documentation, it is time-consuming to go through the documentation.
There is an unofficial Python library called
pynytimesthat provides a more user-friendly interface for working with the NYTimes API.To get started, check out Introduction to pynytimes.
Hidden API
Hidden API
Most industry-scale websites display data from their database servers.
- Many of them do NOT provide official APIs to retrieve data.
Sometimes, it is possible to find their hidden APIs to retrieve data!
Examples:
Hidden API
How can we find a hidden API?
- On a web-browser (FireFox is recommended)
- F12 -> Network -> XHR (XMLHttpRequest)
- Refresh the webpage that loads data
- Find
jsontype response that seems to have data - Right-click that response -> Copy as cURL (Client URL)
- On an API tool such as Python curlconverter,
- Paste the cURL to the curl command textbox, and then click “Copy to clipboard” right below the code cell.
- Paste it on your Python script, and run it.
Details on requests methods
Our course contents are limited to the very very basics of the
requestsmethods.For those who are interested in the Python’s
requests, I recommend the following references:
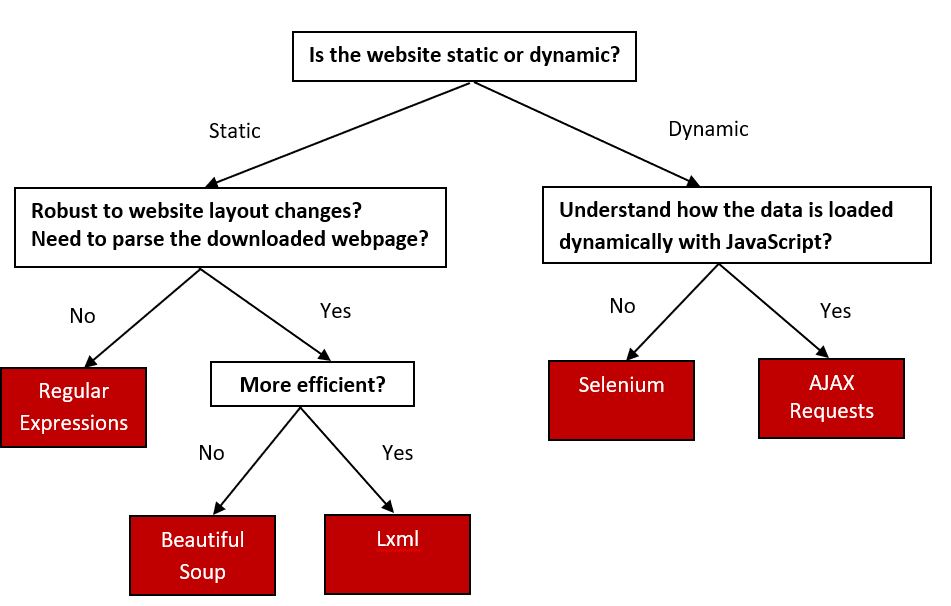
FYI on Web-Data Collection Approaches
Using Hugging Face’s Free LLM API
What is Hugging Face?
- A platform hosting thousands of open-source Language Models (LLMs), including text classification, summarization, question-answering, etc.
- Free to use for many models via the Inference API.
How to Get a Free Token
- Create a Hugging Face account at huggingface.co.
- Go to your Profile → Settings → Access Tokens.
- Click New token → Give it a name → Choose Read role.
- Copy the generated token (looks like:
hf_xxx...). Keep your API token private.
Editing API Token Permissions
- On the Access Tokens page, you’ll see a list of your existing tokens.
- Typically, you can select a token and look for an Edit or … (ellipsis) option to change its permissions.
- If you do not see an option to edit permissions:
- You may need to create a new token with the desired permissions. Some tokens are fixed after creation.
- Check that you’ve granted the following if you need summarization:
- Inference: “Make calls to Inference Providers”
- Repositories (Read): “Read access to contents of all repos under your personal namespace”
- Optionally: other read privileges, if your project needs them.
API Endpoint
- Inference API URL: Each model has a unique endpoint.
- For example, facebook/bart-large-cnn (a summarization model) uses:
https://api-inference.huggingface.co/models/facebook/bart-large-cnn
What Does This API Do?
- Takes your text as an input (prompt).
- Returns a summarized version of that text (or some other transformation, depending on the model).
- Example: Summarizing multiple movie plots into one concise paragraph.
Example Code Snippet
# Text you'd like to summarize
text_to_summarize = """
Summarize the following movie plot in a sentence.
Four misfits are suddenly pulled through a mysterious portal into a bizarre cubic wonderland that thrives on imagination.
To get back home they'll have to master this world while embarking on a quest with an unexpected expert crafter.
"""import requests
# Your Hugging Face token (replace with your real token)
HF_API_TOKEN = "hf_your_real_token_here"
# The summarization model's API URL
API_URL = "https://api-inference.huggingface.co/models/facebook/bart-large-cnn"
# Add your token to the request headers
headers = {"Authorization": f"Bearer {HF_API_TOKEN}"}
payload = {"inputs": text_to_summarize}headers: The “Authorization”: “Bearer …” header lets Hugging Face know you have permission to use their API.payload: The {“inputs”:} tells the model what text to summarize. requests.post(): Sends your text to the model’s endpoint.
# Send POST request
response = requests.post(API_URL, headers=headers, json=payload)
# Check response and extract the summary
if response.status_code == 200:
output = response.json()
summary = output[0]["summary_text"]
print("\nSummary from Hugging Face Inference API:")
print(summary)
else:
print(f"\nAPI request failed with status code {response.status_code}:")
print(response.text)