Lecture 10
Pandas Fundamentals V: Reshaping and Joining DataFrames
April 20, 2026
✨ Tidy DataFrame
Variables, Observations, and Values

A
DataFrameis tidy if it follows three rules:- Each variable has its own column.
- Each observation has its own row.
- Each value has its own cell.
- Each variable has its own column.
A tidy
DataFramekeeps your data organized, making it easier to understand, analyze, and share in any data analysis.
🔁 melt() and pivot(): Overview
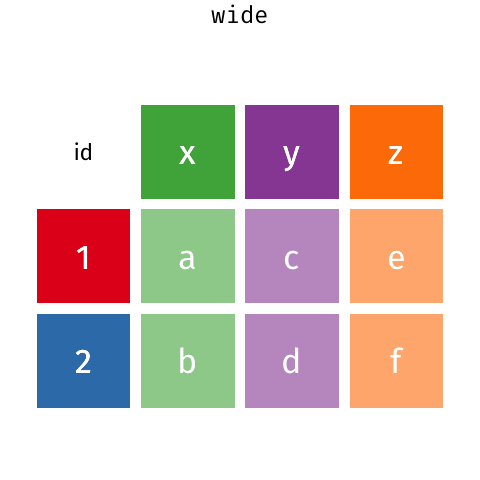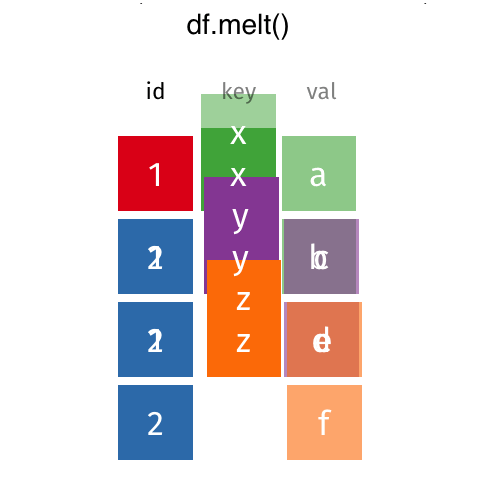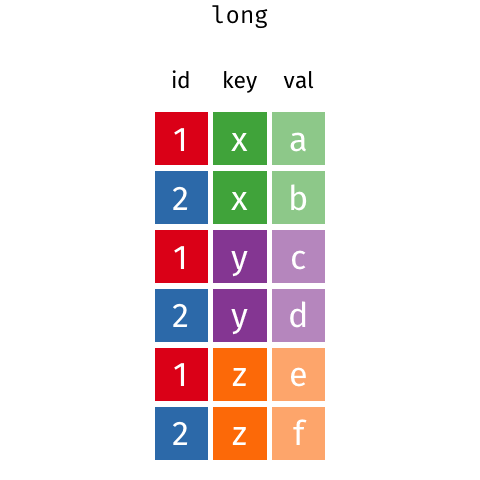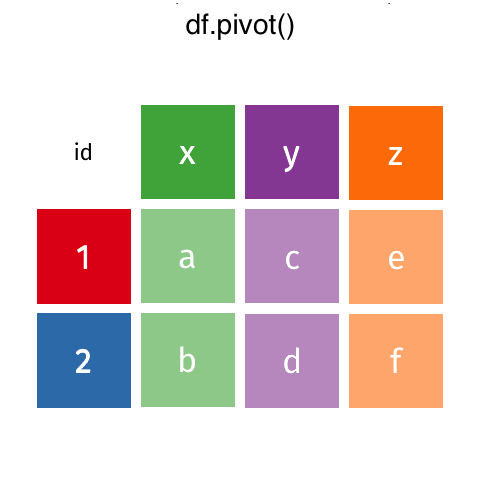
melt()makesDataFramelonger.pivot()makesDataFramewider.
🔗 Joining DataFrames with merge(): Setup
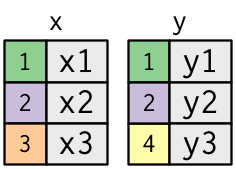
- The colored column represents the “key” variable.
- The grey column represents the “value” variable.
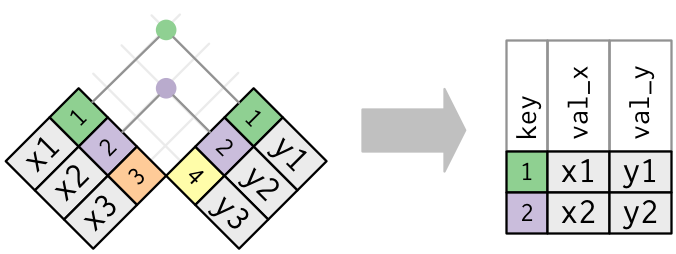
🎯 Inner Join
An inner join matches pairs of observations whenever their keys are equal:
⬅️ Left Join
A left join keeps all observations in x.
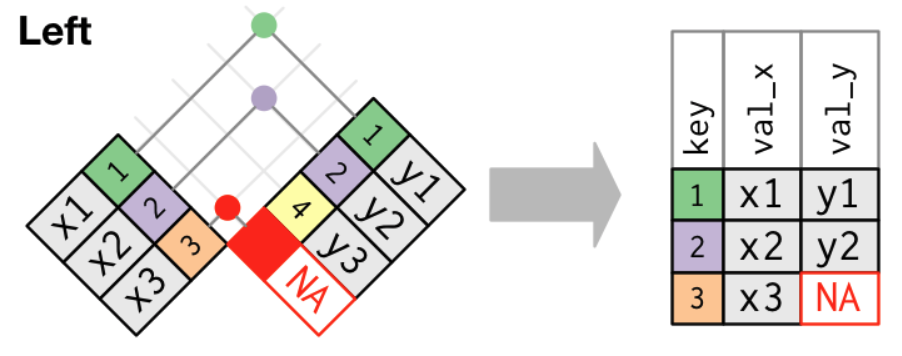
- The most commonly used join is the left join.
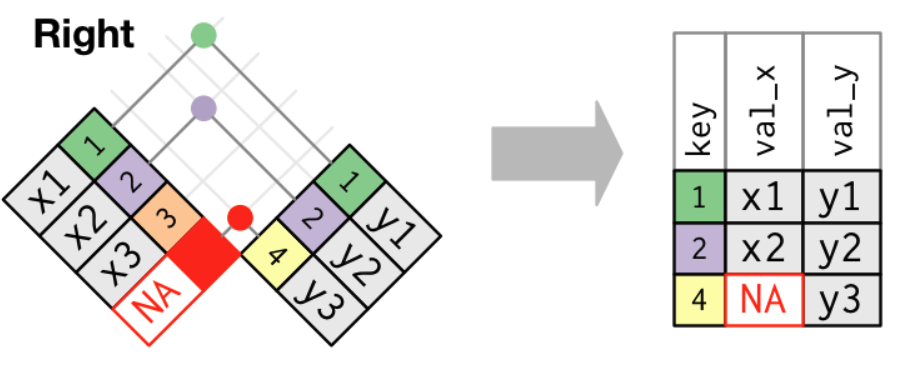
➡️ Right Join
A right join keeps all observations in y.
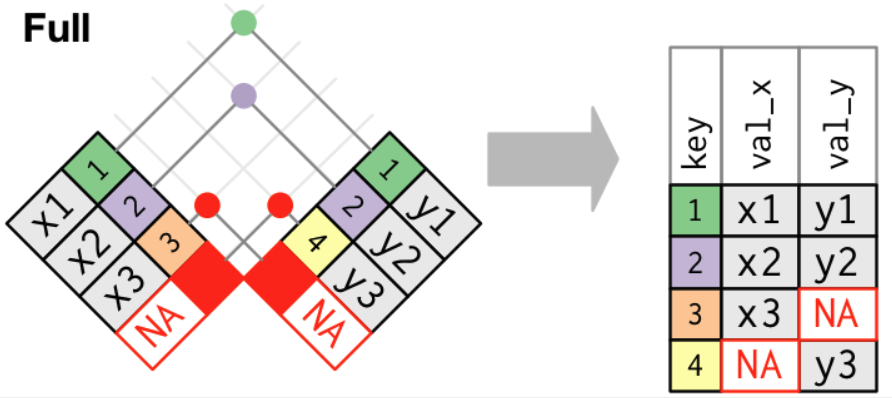
🌐 Outer (Full) Join
A full join keeps all observations in x and y.
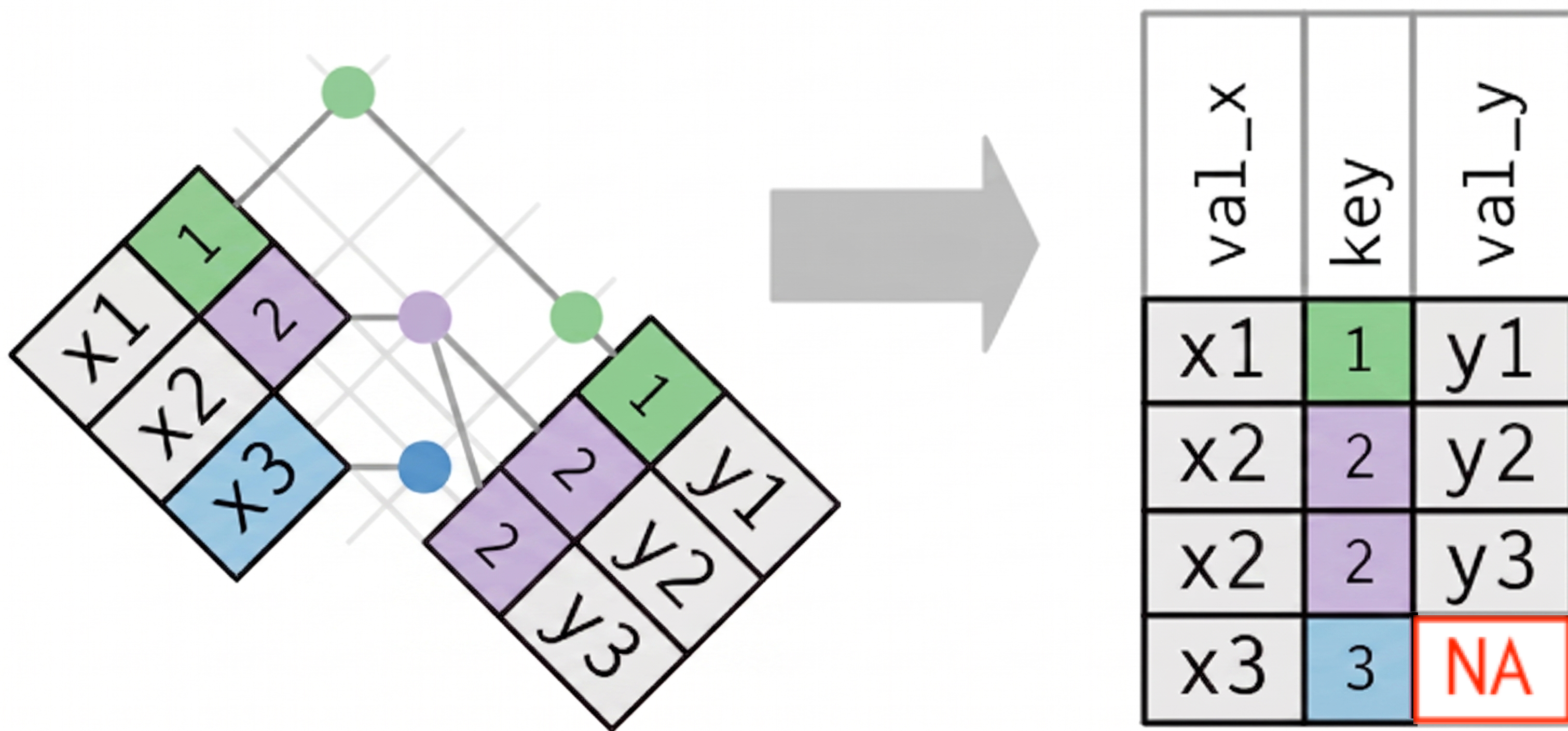
🔢⦂1️⃣ Duplicate Keys: Many-to-One
The left DataFrame has duplicate keys (a many-to-one relationship).
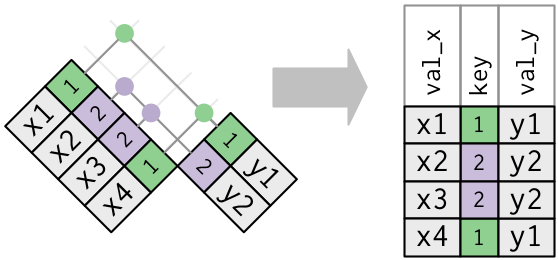
1️⃣⦂️🔢 Duplicate Keys: One-to-Many
The right DataFrame has duplicate keys (a one-to-many relationship).
- Although this is a left join, the resulting DataFrame
one_to_manyhas more observations thanxbecause one row inxcan match multiple rows iny.
🔢⦂🔢 Duplicate Keys: Many-to-Many
Both DataFrames have duplicate keys (many-to-many relationship).
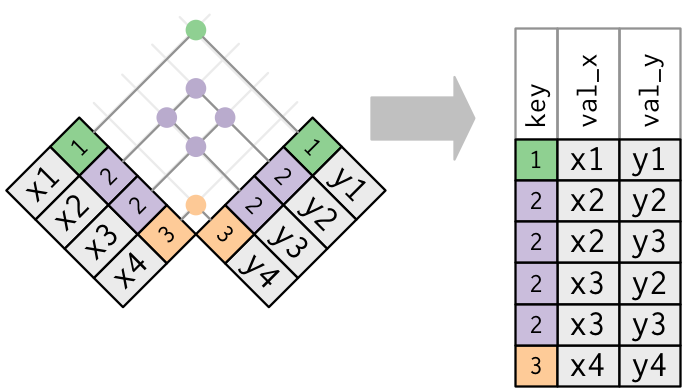
- In practice, it is better to avoid the many-to-many join.