Lecture 3
Data Collection I: DataFrame; Spyder IDE; Scrapping Web-tables with pd.read_html()
February 9, 2026
Pandas Series and DataFrame
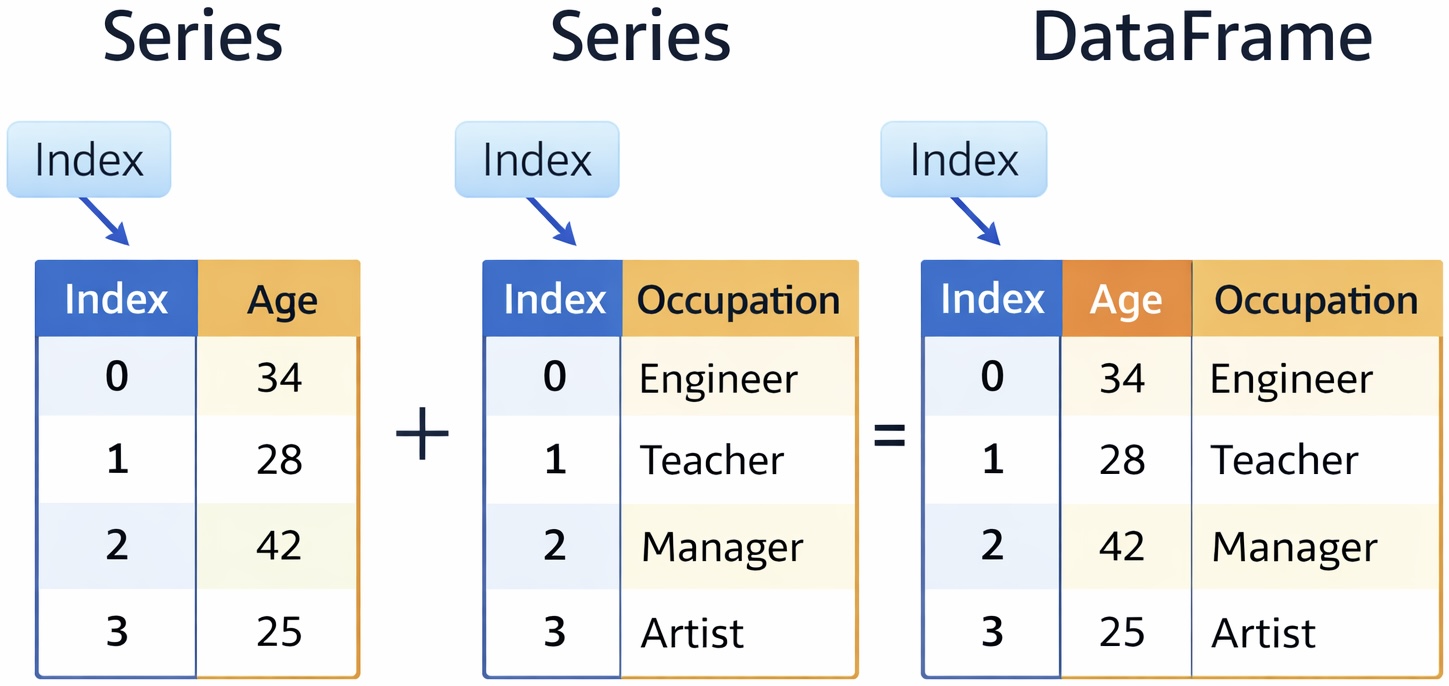
Series: A one-dimensional object containing a sequence of values (like a list).DataFrame: A two-dimensional table made of multipleSeriescolumns sharing a common index.
✨ Tidy DataFrame
Variables, Observations, and Values

A
DataFrameis tidy if it follows three rules:- Each variable has its own column.
- Each observation has its own row.
- Each value has its own cell.
- Each variable has its own column.
A tidy
DataFramekeeps your data organized, making it easier to understand, analyze, and share in any data analysis.
📝 Script Editor
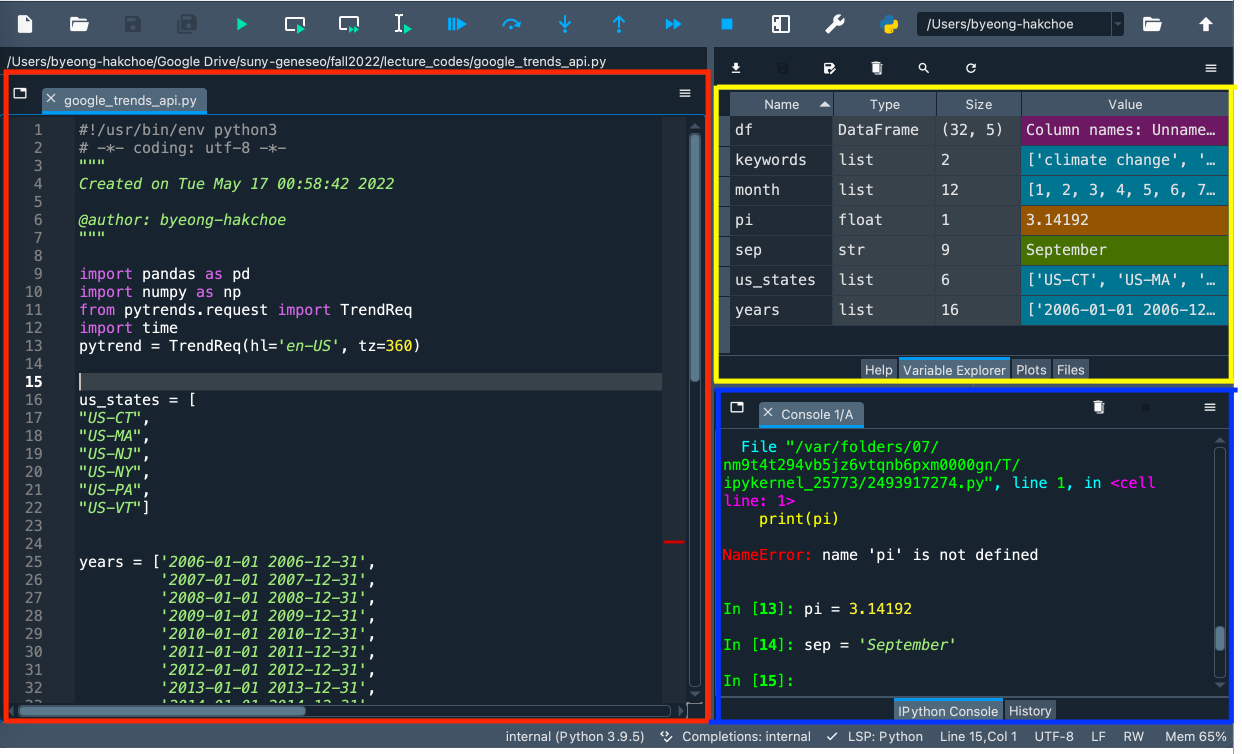
- From Script Editor (red box), we can create, open and edit files.
🖥️ Console Pane
- From Console Pane (blue box), we can interact directly with the Python interpreter, and type commands where Python will immediately execute them.
🔍 Variable Explorer
- From Variable Explorer (yellow box), we can see the values of variables, data frames, and other objects that are currently stored in memory.
📦️ Data Containers in Variable Explorer
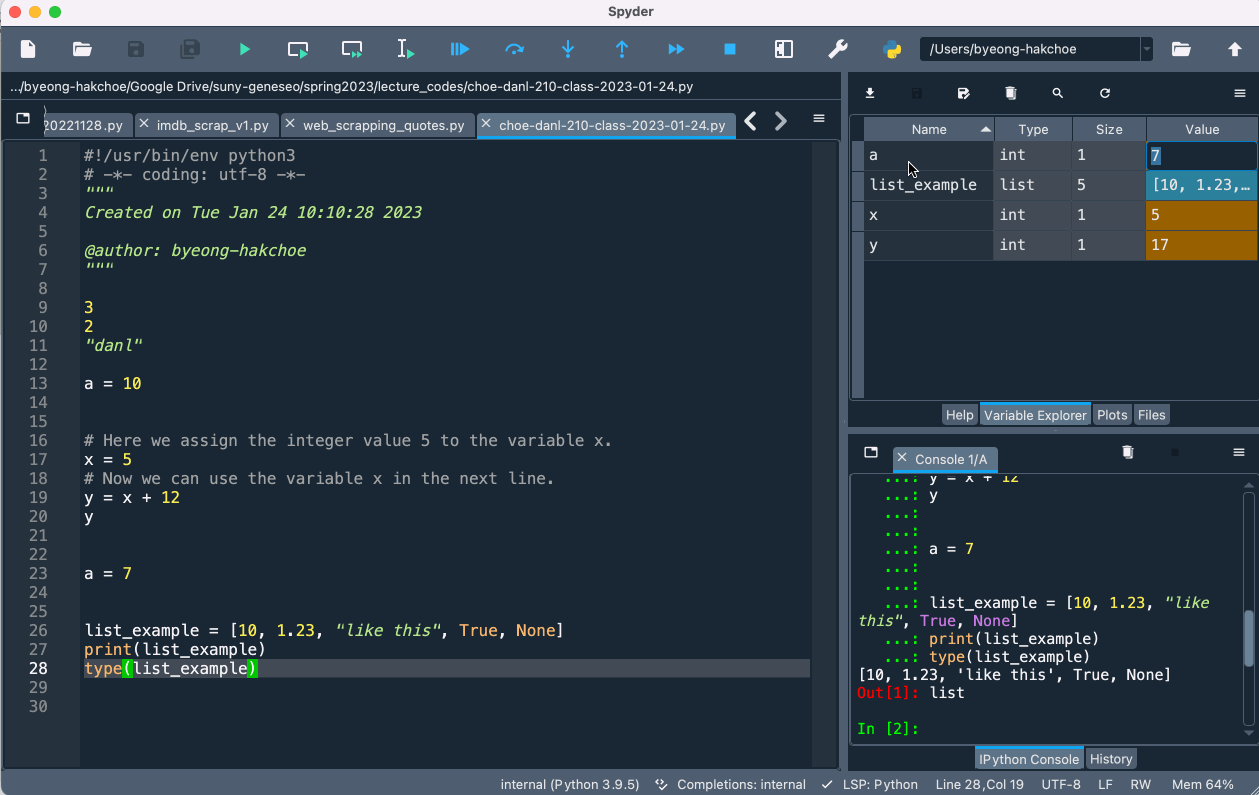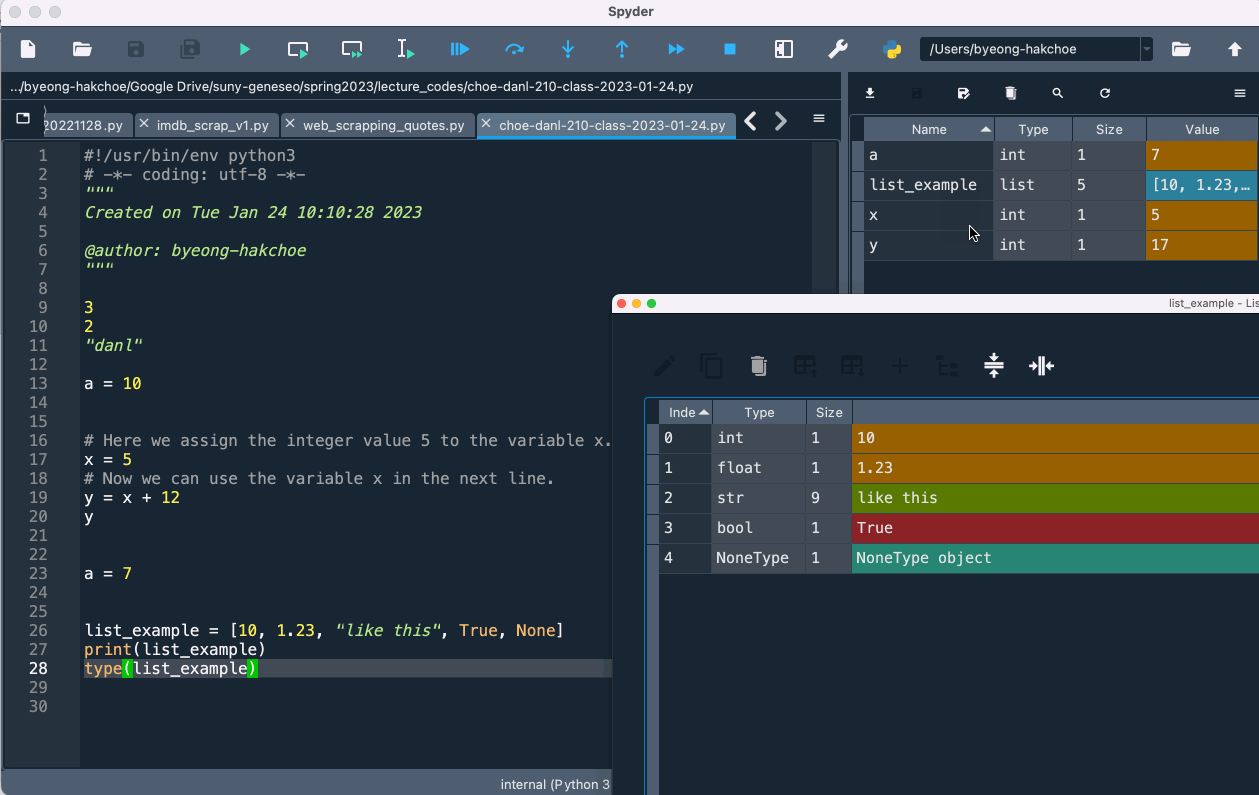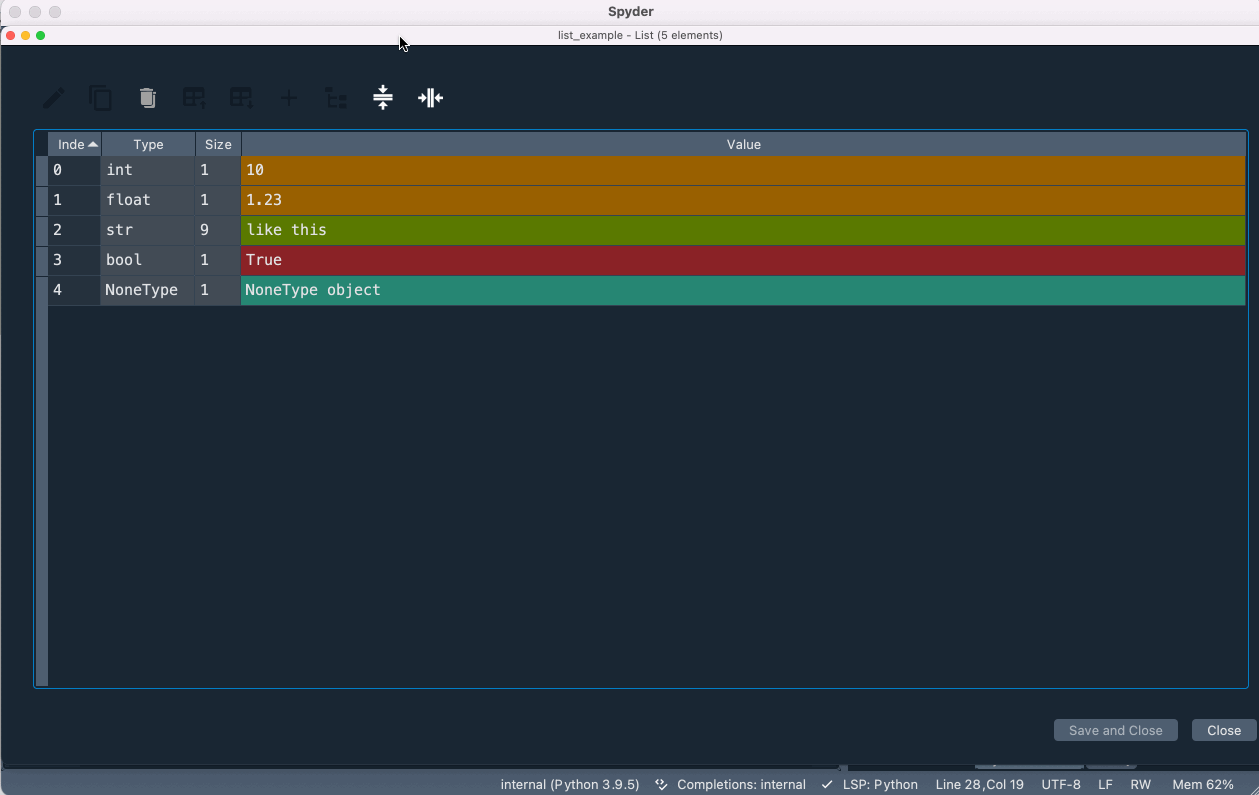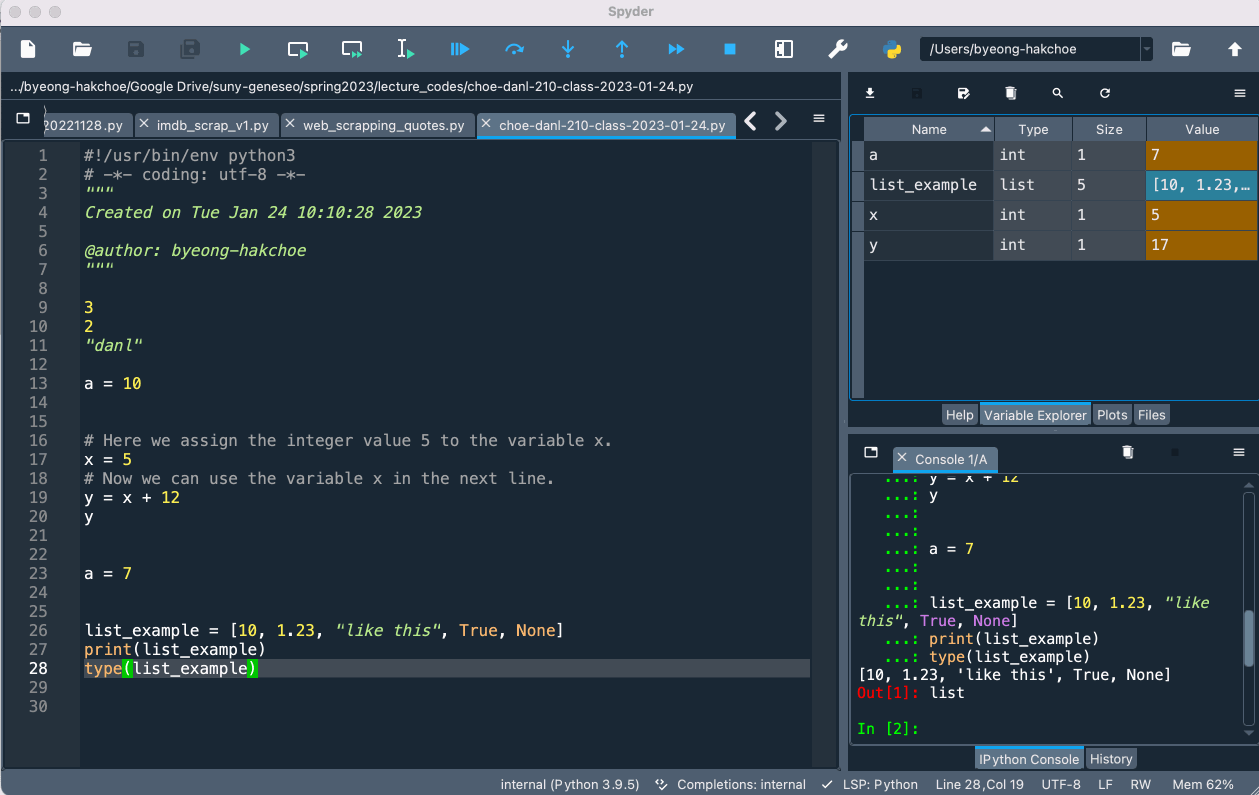
- If we doucle-click the objects such as
listandDataFrameobjects, we can see what data are contained in such objects.
💬 Comments, Code Cells, and Keyboard Shortcuts
The
#mark is Spyder’s comment character.It is recommended to use a coding block (defined by
# %%) with block commenting (Ctrl/command + 4) for separating code sections.To set your keyboard shortcuts,